Windows Azure and Cloud Computing Posts for 6/13/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Jerry Huang described how to Use Gladinet Cloud Solutions with Windows Azure Storage Emulator in a 6/12/2011 post to his Gladinet blog:
The Windows Azure storage emulator provides local instances of the Blob, Queue, and Table services that are available in the Windows Azure. If you are building an application that uses storage services, you can test locally by using the storage emulator.
Gladinet has full support for Windows Azure Blob Storage. Now for those of you that develop Azure based application using local emulator, you can use Gladinet Cloud Desktop to connect to Azure Emulator and map it as a local drive too.
Step 1 – Setup Azure Storage Emulator
First you will need to download Azure SDK and install it. After installation, you will have it in the Start Menu.
Next you will follow the instruction from MSDN to initialize the local storage emulator. Basically you will use the Azure SDK Command Prompt and run the DSInit command.
The correct syntax is: DSInit /sqlInstance:SQLEXPRESS
(assuming SQLEXPRESS is the name of a local instance of SQL Express)
Once it is successfully initialized, a dialog like the one below will show up.
Step 2 – Run the Storage Emulator
To run the Azure Storage Emulator, you will need to run the Storage Emulator from the Azure SDK.
When the storage emulator is running, you will see it from the system tray.
Step 3 – Map a Drive to Azure Storage Emulator
In the next screen, always use http://127.0.0.1:10000 as the EndPoint.
For the Primary Access Key, use:
Eby8vdM02xNOcqFlqUwJPLlmEtlCDXJ1OUzFT50uSRZ6IFsuFq2UVErCz4I6tq/K1SZFPTOtr/KBHBeksoGMGw==
After that, the Azure local storage emulator will be mounted as a virtual drive.
You will need version 3.2.672 and above for the support of Azure Local Storage Emulator. The support starts with Gladinet Cloud Desktop and will be in CloudAFS and Cloud Backup too.
Related Posts







Mark Teasdale (@MTeasdal) posted Azure Blob Storage Basics Part 1 on 6/12/2011:
In Azure we have four main storage options and these are Table, Sql Azure, Blobs and Queues. This goes up to five if you include local file storage however because of its temporary nature it should not be seen as a serious contender for a storage solution. Each of the four storage has its own merits but in this blog we are going to look at blob storage. In subsequent posts I will delve further into the blob storage service but for now my main aim is to get you comfortable with what it is about.
Binary Large Objects (BLOBS) are typically large in size and usually are seen as mp3, image or video files but could just as easily be large message attachments sent over a SOA system. Traditional storage solutions have centered around either the filesystem or the database and each of these have suffered from issues of latency, expense of storage and resilience.
In Azure we store blobs on the filesystem but make them accessible either through the rest api or a .net wrapper around the api known as storage client library. Which one you use is really up to you but I think most .net developers are going to go with the wrapper purely on productivity grounds alone. The wrapper for example gives you intellisense support within Visual Studio. As an aside we have Azure Drive, this effectively makes blob storage accessible through the file system of an instance. There are two caveats with Azure Drive firstly you can only use it within the confines of the data centre that house the instance to which the drive is attached. This prevents on premise solutions from accessing the drive, every thing has to be in the cloud. Also it is attached to one instance and as such other role instances have read only access to it.. so it is limited. This may change. Its main advantage is speed as it bypasses the whole stage of brokering requests through a rest interface.
One of the main questions you have to ask yourself is how you are going to use blob storage. You should remember that performance is always going to be an issue with storage and if you are architecting a solution that accesses blob storage then the best performance is going to be a solution that is also within the same data centre as the storage solution. That said it is perfectly feasible to use the rest based storage as a backup solution for on premise applications. You just have to be clear about your tradeoffs and what are the important aspects of the solution application.
Blob Storage Fundamentals
All storage solutions are attached to account. When you create an account in Azure the URI for queues, tables and blobs are associated with that account
The screen shot above shows a storage account I have created in Azure. Also note some of the properties of this account
We have three URL’s for accessing our storage on one account. The URL’s default domain is core.windows.net. This is not set in stone and we can configure Azure to use our own custom domain names by changing the CNAME property. I will cover this later in a seperate post. Also note we can specify the data centre we want our storage to be located in, here I have chosen North Europe. We may have compiance issues concerning where the data is stored that make this a crucial choice.
So how is this all structured within the Azure world ?
The blob file lives within a container that is associated with an account. The common way of looking at containers is to see them as similar in function as a folder on the filesystem. Containers are a way of setting access to the blobs within them rather than specifying access permisssions on each individual blob file within them. There are two settings Private and Public. Private containers are only available to the person who created the account. When you try to access the elements within a private container you will be prompted for an access key. Public on the other hand gives every body read only access but you will need the access key to manipulate them.
When creating accounts it is best to have an account per application.
Developing with Azure Blob Storage
Our article http://azurehorizons.com/blog/2011/06/azure-dynamic-configuration/ shows you how to define a connection strings in the Web.Config equivalent of the Web.config. It is always best to specify your account settings within config rather than code because it allows us to easily change betewwn environments without having to recompile code.
We are going to show you some examples of creating containers in this article and the next post will look at how to use and manipulate blobs within these containers.
Typical code to create containers is shown below
These would be typical connection string properties within the definition and configuration files.
Once we have these in place we can create a container that will hold our blob files. Firstly if we are using the sdk version 1.4 we need to have this code in a central location. Typically for a web role we will have it in a global.asax file.
We will worry about this later but for now just take it as red that we need this code somewhere.
To create a container via the api then we can code the following
Here we are creating the container from the click of a button. We are create an instance of the account using the settings we specified earlier in our configuration. For development purposes we use the UseDevelopmentStorage = true setting but we would swap that out for our live accounts.
Once we have got our account we create a client instance and then generate the container from the client. The create method genrates an HTTP request to the BLOB storage service to create the container. The default permissions on this container will be private. The same code as above but with container.Delete() will delete the container. To list containers we simply call blobClient.ListContainers() and bind the results to a control.
As you can see we are interacting with the api in a standard manner, following familiar steps of creating a connection to the underlying storage and then generating what we want from the client connection.
Interacting with the development storage
When we are developing, its nice to see that we are interacting with storage properly.
If you right click the azure symbol in the system tray and choose show storage emulator UI we can see the endpoints of our dev storage and start and shut them down at will.
A nice little tool you can download http://azurestorageexplorer.codeplex.com/. This tool allows you to view any files added to storage, delete those files and also interact with the account and container from a nifty ui.
We can use this tool to make sure that our code is working and creating, deleting containers and blob files. Remember that in the devfabric world storage is mimicked and Sql Server is used behind the scenes.
This article showed us the basics of creating and manipulating containers, in the next article we will look at manipulating other properties on the container and posting blob files out to them. This is the taster before the main course !!!









Greg Oliver (@GoLiveMSFT) explained Automating Blob Uploads in a 6/11/2011 post to his Cloud Comments blog:
In my travels I hear about a lot of patterns of cloud computing. One that I hear frequently is “upload a file and process it”. This file could be financial data, pictures, video, electric meter readings, and lots more. It’s so common, and yet when I Bing (yes, Bing) for blob uploaders, they’re all manual.
Architecture View
Process Flow
Sorry for the eye chart. I’ll try to explain (in order of the basic system flow.)
UI Thread
A FileSystemWatcher detects new files in a directory in the local file store. A tracking record is inserted into a SQL Express tracking DB.
Process Files Thread
If it’s a big enough file that the upload is attempted before the file is fully copied into the directory, the thread waits by attempting a write lock. The file is uploaded to Azure blob storage using parallel blocks. The block size and number of simultaneous blocks is configurable using the StorageClient API. Once the file is uploaded, a record is placed into the Notification Queue and the tracking record is updated.
Azure Worker
The Azure worker detects the notification, determines that the blob is “ok” in some way (application specific), acknowledges receipt (in order to free up client resources), processes the blob (or sets it aside for later), then deletes the notification message.
Process Acknowledgements Thread
Receipt of the acknowledgement message triggers deletion of the file in the upload directory and update of the tracking record. Then the acknowledgement message is deleted.
What could go wrong?
In a manual upload scenario, so many controls would get in the way. Automating the process demands that care is taken to ensure fault tolerance. Here are some things that can go wrong and how the architecture protects against them:
- Azure worker is unavailable. (Perhaps it’s being upgraded, it’s very busy, it has a specific window of time that it runs.)
By placing the data into blob storage and creating the notification record, the system is unaffected by absence of the worker. If you need more workers to process the data, they can easily be created and will immediately start taking load. This procedure can be automated or manual.- Azure worker fails. (Hardware? Program bug?)
The last step in the process is deleting the notification message. The message will re-appear in the queue for processing by another worker in this case. You should check the number of times the message is de-queued to ensure the message or data in themselves aren’t the problem.- Upload fails. (Network connection?)
The upload is protected in a couple of ways. By uploading in blocks, if your upload fails in the middle you only need to upload the missing blocks. The last block that’s uploaded stitches the component blocks together. Also, the last step in the upload process is update of the tracking record. If the tracking record is not updated, the upload will be attempted again at a later time.- Client resource stretched. (Too many files in the directory.)
Files to be uploaded can come from many sources and perhaps 100’s at a time. By watching for acknowledgement of receipt from the server side the program can recycle this resource effectively. This is the main reason the program was written as a set of cooperating threads – so that a long upload wouldn’t prevent keeping the directory cleaned up.Alternatives to the Process
Following on #4 above, if there’s lots of processing to be done on each data file (blob), but there’s also lots of files to be uploaded, you can run into trouble. If you don’t have enough workers running (costs more), files could back up on the client and potentially cause problems. By splitting the task load up, you will be able to acknowledge receipt of files quicker and clean up on the client more frequently. Just be sure you’re running enough workers to get the overall work done during your window of opportunity.
What about those queues?
Yes, you could use SQL Azure tables to manage your notifications and acknowledgements. Queues have the advantage of being highly available and highly accessible in parallel via HTTP, though this comes at a cost. If you have millions of files to process, these costs are worth considering. On the other hand, presumably your SQL Azure database will be busy with other work and you don’t want to load it down. Also, if you have lots of customers you would need to either wrap access to SQL Azure behind a web service or open its firewall to them all.
What about the FileSystemWatcher?
FSW has a buffer to hold events while they’re being processed by your code. This buffer can be expanded, but not infinitely. So you need to keep the code in your event logic to a minimum. If large numbers of files are being dropped into the upload directory, you can overwhelm the buffer. In a case like this it might make sense to set up multiple incoming directories, multiple upload programs, etc. An alternative to FSW is enumerating files, but this can be slow.
As always, I’m interested in your thoughts. Comment freely here or send a mail. Full source for both client and server are here.


<Return to section navigation list>
SQL Azure Database and Reporting
The SQL Server Team announced a SQL Server JumpIn! Camp: Engineers helping engineers but didn’t divulge the date, time or location:
As part of Microsoft’s commitment to participate in and contribute to the PHP community we’re excited to be working together with some of the key PHP applications in the world. The first SQL Server JumpIn! camp was a huge success and we expect this one to be even more so! We look forward to four rewarding days of engineers helping engineers through hands-on programming, discussions and mutual learning.
Our list of participants include: Agavi, AuraPHP, CakePHP, Frapi, MediaWiki, OpenVBX/Twilio, Pear, Symfony, Voce Communications, Web2Project, and Zend.
Kicking off the camp will be Ted Kummert, Sr. VP of the Business Platform Division, who is responsible for leading SQL Server product strategy and development. Joining him will be Nigel Ellis, Distinguished Engineer in Microsoft’s Business Platform Division, who leads the development work for SQL Azure.
We have some great activities planned, so it’s not all work but also some play in the Seattle area, including dinner for all at the Space Needle.
We are looking forward to an exciting event! [SQL Azure emphasis added.]
Strange not to give event details. Here’s the post from the JumpIn! blog:
This June 20-23rd 2011 jump deep into SQL Server and leverage the PHP driver for SQL Server 2.0 and its support for PDO
After the huge success in November 2010; the Microsoft SQL Server corporate team is proud to announce that it is sponsoring its second SQL Server JumpIn! camp for developers to exploit the functionality offered by the new PDO driver to support SQL Server and SQL Azure.
Work side-by-side with the SQL Server engineers to ensure that your application works flawlessly with SQL Server/Azure. This camp is planned to be rewarding, interactive, and hands-on. It’s an excellent opportunity to interact with other contributors and the SQL Server team!
This intense camp also offers the opportunity to extend the reach of your project(s); as 70% of small businesses use SQL Server and almost all the larger businesses do.
A quick recap of the SQL Server JumpIn! camp in November 2010
By all measures, we consider this camp a major success! This sentiment is reflected by all the participants! While the blogs haven't started to roll in yet, tune in to twitter with the #jumpincamp hash tag and see it for yourself. Not only did it demonstrate that Microsoft and the open source community can work well together and make good stuff happen, but now we have a much clearer understanding about what we need to do to better support PHP applications on Windows/IIS/SQL Server and the Azure platform. The PHP participants now have a better understanding of how SQL Server works and how PHP applications can best utilize its capabilities, and understand how we are trying to add value to their applications.
Who was at the camp?
17 developers representing 10 PHP projects from several countries rubbed shoulders with Microsoft developers to build Windows, IIS, SQL Server, and Azure Platform support into their applications. In addition, when the situation demanded it, we called in the relevant SQL / IIS experts to provide the expertise for the participants.
Why did they come?
Simply put, SQL Server is an excellent product that has the highest reach among all databases available today. By adding support for SQL Server, these projects stand to gain from the broad customer base that already has SQL Server in their organizations. As I later found out, most of them came prepared to add support for SQL Server, and then notched it up by wanting to complete it at the event itself!!
What were the accomplishments?
A testament to the intense focus and effort from all the participants is evidenced by the following facts. Of the 10 projects at the camp:
- 8 projects had completed enough to demo their applications with SQL Server
- 4 projects actually published a build while at the camp itself
- Kohana, Lithium, XHProf released with SQL Server adapter
- Doctrine released an RC at the event after adding support for SQL Server, SQL Azure and Windows Azure
- ImpressCMS, MODx, Typo3, Formulize, osCommerce & TangoCMS are expected to included SQL Server support in a major milestone in next few months
- 5 projects improved their performance on IIS using our WinCache extension
- Kohana, Lithium, osCommerce, Doctrine, TangoCMS
- It was so easy that some added support for it before the 30 minute presentation was finished!
- 4 projects successfully tested on SQL Azure
- Doctrine, Lithium, Typo3, XHProf
- 4 projects successfully using PDO driver for SQL Server support
- Doctrine, MODx, ImpressCMS, TangoCMS (Typo3 is considering it for v5)
OK, this post gives the dates but not the location or how to register. Even stranger.
Steve Yi posted Video How To: Synchronize and Share Data in a 6/13/2011 post to the SQL Azure Team Blog:
This walkthrough shows how to use SQL Azure Data Sync to provide bi-directional synchronization and data-management capabilities with on-premises and cloud databases. The video covers both the benefits and features of SQL Azure and explains how businesses can use SQL Azure Data Sync to share information efficiently.
We have several other walkthroughs you can watch and download code for. Visit http://sqlazure.codeplex.com .
PenniJ updated a SQL Azure Delivery Guide article on 6/9/2011 for the TechNet Wiki:
Introduction
This delivery guide provides a primer for solution implementers who are starting a project which will (or may) use SQL Azure. The guide is aimed at experienced architects and developers who already have a background with SQL Server and perhaps with the .NET Framework. A good familiarity with T-SQL, SQL Server features and administration, and application architectures based on the Microsoft stack is assumed. The guide familiarizes the reader with the things they need to know to get started designing and delivering solutions which include the SQL Azure data platform.
Planning
The path to an effective SQL Azure solution begins with solid planning. Early architectural decisions will affect the rest of the project and the ultimate success of the solution. Planning the data platform for your scenario involves several key decisions, starting with whether SQL Azure or on-premise SQL Server is the best tool for the job. Assuming SQL Azure will play a role in your solution, there are a variety of potential application architectures to choose from. Certain factors to be understood are the SQL Azure Service Level Agreement (SLA), the impact of latency in the chosen architecture, availability and disaster recovery scenarios, and developer tools.
This section dives into these topics to help you make the appropriate decisions early-on.
Choosing Between On-Premise SQL Server and Cloud SQL Azure
If you are developing a solution which will include one or more SQL Server relational databases, the first architectural/planning decision that must be made is whether to deploy that database to SQL Azure in the cloud or to an on-premise SQL Server instance.
SQL Azure offers an extremely easy-to-use relational database engine which is architected natively as a large-scale, highly available, multi-tenant cloud service.
There is an economic and operational argument for eliminating onsite hardware and software and all the upkeep that goes with it. And extending the reach of the database and possibly other application components outside the enterprise firewall can enable many new scenarios.
How to decide for SQL Azure, when sometimes on-premise SQL Server appears to be the more appropriate choice? There are differences in the breadth of functionality provided by the two products. There are different capacity constraints, and some features behave differently between SQL Azure and traditional on-premise SQL Server. At the end of the day, the most important consideration is what will lead to a successful solution and a satisfied customer? The choice between SQL Azure and on-premise SQL Server should be made with this as the fundamental criterion.
The decision tree in Figure 1 illustrates some of the factors that should go into making the choice between SQL Azure and on-premise SQL Server.
Figure 1 - Choosing Between SQL Azure and On-Premise SQL Server
As Figure 1 shows, there are several decision points (technical, economic, and policy-related) which may lead you one way or the other.
It is worth noting that requirements for unstructured storage are not considered a deciding factor between the two options. With on-premise SQL Server, you have SQL’s binary and large text data types available, as well as FILESTREAM storage and all the resources available from the Windows operating system (file system, MSMQ, etc.). With SQL Azure, SQL’s binary and large text data types are also available, although FILESTREAM storage is not supported. Windows Azure tables, blobs and queues round out the support for unstructured storage. So, a combination of structured and unstructured storage needs can most likely be met equally well on-premise or on the Azure platform.
Once decided that SQL Azure is the right choice for your solution, you will also need to choose the edition (Web or Business), the database size (various choices between 1 GB and 50 GB) and the geographic location(s) at which the database(s) are hosted. (Because this guide is focused on SQL Azure rather than on-premise SQL Server, no further detail is provided here about the on-premise path.)
Figure 2 provides a decision path through the edition and size options for SQL Azure between the Web and Business Editions of SQL Azure.
Figure 2 - SQL Azure Database Choices
The geographic location depends on where your users are, to what degree you want to exploit geographic distribution for disaster tolerance, and what regulatory/compliance factors, if any, apply to your situation.
The following table lists the SQL Azure hosting locations at the time of this writing. There is no important technical difference between the data centers, other than their location. Note that bandwidth from the Asia data centers is currently priced higher than others.

Notes on Compliance
A key factor in making the data platform decision is compliance with relevant regulations or laws related to data handling. Depending on the data involved and the country, or other jurisdiction, there may be limitations on where and how data can be stored. This step from the decision tree in Figure 1 (“Can SQL Azure satisfies compliance requirements?”) is expanded into greater detail in Figure 3.
Figure 3 - Evaluating Compliance Factors Related to SQL Azure vs. On-Premise Data Hosting
As Figure 3 indicates, there are a number of things which could impact how you can handle data in your solution. Additional notes on some of these considerations are provided in the table below.




The article continues with many more meters of details.
Liam Cavanagh (@liamca) described How to Visualize your Spatial data in SQL Azure in a 6/5/2011 post to his new Cloud Data Services blog (missed when posted):
One of the most common things I do with SQL Server Management Studio is quickly query a table and see the results. As I have been working with spatial data I have been impressed at how easy it is to also query and view your spatial data. If you have not tried this, here is an example of how it works.
If you do not already have a table that contains spatial data, here is a script that will create a table with spatial data in it. Please note, that although this table only has 3 rows (one for each country), it contains polygons with over 108,000 points in them and make take a little time to load. By the way, if you are interested in seeing this yourself, try executing the following query:
select the_geo.STNumPoints() from countries
After using the above script, you can click on “New Query” and execute a query like “Select * from Countries” as you normally would. Notice however, that this time the results includes a tab called “Spatial Results”. If you click on this, it will show the results of your spatial data in a visualized format. On this page you can zoom in and out and also apply labels to the visualizations. For example, from the “Select label column” choose “NAME” and notice how it overlays the results of this column on top of the map.
SQL Server Management Studio Spatial Query

Liam mentioned in an earlier Welcome to my Cloud Data Services blog post that he’s moved from the Windows Azure Data Sync project to the Cloud Data Services group and started a new blog. (Subscribed.)
Liam Cavanagh (@liamca) explained How to load spatial data into SQL Azure in a 6/5/2011 post to his Cloud Data Services blog (missed when posted):
I recently had the need to load some data into SQL Azure. For those of you who don’t know, SQL Azure has the same Geography and Geometry datatypes that you find in SQL Server. This is great because you can load huge amounts of spatial data into SQL Azure and through the use of spatial indexes have a really efficient way of retrieving spatial data from the cloud. In this post, I want to give you an example of an application you could use to easily load Esri Shapefile data into SQL Azure. I would like to point out that this code is really just a staring point and there are a lot of efficiencies that could be done. Or you could always use a tool like FME from Safe Software to do this also.
New Shapefile Importer Project
Next I needed was a way to read the Shapefiles. Luckily Esri had posted a Codeplex project that is a Shapefile Reader with a library that was capable of reading ShapeFiles. This is perfect, because it really helped to do about 90% of what I ultimately needed to do. What this library will do is take a Shapefile (which actually consists of multiple files), load them, parse the file and determine if the data is a point, polygon, multipologon, etc and also give you the actual rows.
Within your “Shapefile Impoter” directory, create a new directory called “Shapefile Reader” and download this libary and into this directory.
Shapefile Reader
After doing this, go back to your Visual Studio project and include this project by right clicking on the solution in the Solution Explorer and choosing Add | Existing Project. Search for the Catfood.Shapefile.csproj file and open it.
Most likely you will need to walkthrough the upgrade it to the version of Visual Studio you are using. After that is done, you should be able to right click on the Catfood.Shapfile project and build it.
We will need to add a reference to this library in your main project so right click on the “References directory” in your “Silverlight Importer” project and choose “Add Reference”. Within Projects tab, you should see the Catfood.Shapefile project. Choose this. NOTE: If you do not, you may need to build the Catfood.Shapefile project.
Add Shapfile Reader Library
Now we can get to the coding. Open the program.cs file and add a reference to this library and the SQL Server client (to allow us to access SQL Azure).
using Catfood.Shapefile;
using System.Data.SqlClient;In Main add the following code:
// Pass the path to the shapefile in as the command line argument if ((args[0] == "import") && (args.Length == 5)) ImportShapefile(args[1], args[2], args[3],args[4]); else { Console.WriteLine("Usage: \"Shapefile Importer.exe\" import <shapefile.shp> <SQL Azure Connection String> <tablename> <srid>"); Console.WriteLine("Example: \"Shapefile Importer.exe\" test.shp \"Server=qadhfyp8ym.database.windows.net;Database=SpatialDB;User ID=admin@qadhfyp8ym;Password=myPassword;Trusted_Connection=False;\" Spatial 4326"); }This will allow your console applicaton to accept the shapefile name, the SQL Azure connection string, the table name to store the data in and the coordinate system to use.
Next we will create a new function called ImportShapeFile to receive these parameters and do the actual work.
protected static void ImportShapefile(string shapeFileArg, string connString, string tableName, string srid) { }In order to create the table we need to know what columns exist in the shapefile. To do this we will leverage the Esri library, scan the file and determine the datatypes. I have to admit, this this could be enhanced a great deal because right now I assume all columns are varchar and it really should do a better datatype matching. In the ImportShapefile function add the following code:
// construct shapefile with the path to the .shp file string geom = ""; string colString = ""; // Get the column names and the max length // For now I am making them all varchar columns // Later it should be extended to support other data types string[] columnName = new string[128]; int[] maxLen = new int[128]; int shapeCounter=0; int columnCounter=0; try { Shapefile shapefile = new Shapefile(shapeFileArg); Console.WriteLine("Scanning Shapefile Metadata: {0}", shapeFileArg); Console.WriteLine(); //int processed = 0; foreach (Shape shape in shapefile) { Console.WriteLine("Shape {0:n0} - Type {1}", shape.RecordNumber, shape.Type); // each shape may have associated metadata // I will infer the datatype from the values string[] metadataNames = shape.GetMetadataNames(); if (metadataNames != null) { shapeCounter = 0; columnCounter = 0; foreach (string metadataName in metadataNames) { if (shapeCounter == 0) columnName[columnCounter] = metadataName; if (shape.GetMetadata(metadataName).Length > maxLen[columnCounter]) maxLen[columnCounter] = shape.GetMetadata(metadataName).Length; else if (maxLen[columnCounter] <= 0) // Need to be at least 1 char in length maxLen[columnCounter] = 1; columnCounter += 1; } shapeCounter += 1; } else { Console.WriteLine("No metadata available."); return; } //++processed; //if (processed == 1000) break; } } catch (Exception ex) { Console.WriteLine(ex.Message); Console.WriteLine(); return; }In the final section, we will take this information and use it to create a new table and actually import the data. Add the following code after the above code.
// Connect to the database and create the table try { Shapefile shapefile = new Shapefile(shapeFileArg); SqlConnection sqlAzureConn = new SqlConnection(connString); sqlAzureConn.Open(); SqlCommand nonqueryCommand = sqlAzureConn.CreateCommand(); // If the table exists then drop it string shortTblName = tableName; if (tableName.IndexOf(".") > -1) shortTblName = tableName.Substring(tableName.IndexOf(".") + 1, tableName.Length - tableName.IndexOf(".") - 1); nonqueryCommand.CommandText = "if EXISTS (SELECT 1 from sysobjects where xtype='u' and name = '"+shortTblName+"') DROP TABLE " + tableName + ""; Console.WriteLine(nonqueryCommand.CommandText); Console.WriteLine("Number of Rows Affected is: {0}", nonqueryCommand.ExecuteNonQuery()); nonqueryCommand.CommandText = "CREATE TABLE " + tableName + " ( "; for (int i= 0; i<columnCounter; i++) { nonqueryCommand.CommandText += "["+ columnName[i] + "] varchar("+maxLen[i]+") null,"; } nonqueryCommand.CommandText += "[geom] [geometry] NULL, [geo] [geography] NULL )"; Console.WriteLine(nonqueryCommand.CommandText); Console.WriteLine("Table Created: {0}", nonqueryCommand.ExecuteNonQuery()); nonqueryCommand.CommandText = "create clustered index " + shortTblName + "_idx on " + tableName + " (" + columnName[0] + ")"; Console.WriteLine(nonqueryCommand.CommandText); Console.WriteLine("Index Created: {0}", nonqueryCommand.ExecuteNonQuery()); Console.WriteLine("Importing Shapefile: {0}", shapeFileArg); Console.WriteLine(); // enumerate all shapes foreach (Shape shape in shapefile) { Console.WriteLine("Shape {0:n0} - Type {1}", shape.RecordNumber, shape.Type); nonqueryCommand.CommandText = "Insert into " + tableName + " ("; for (int i = 0; i < columnCounter; i++) { if (i > 0) nonqueryCommand.CommandText += ", "; nonqueryCommand.CommandText += "[" + columnName[i] + "]"; } nonqueryCommand.CommandText += ", geom) values ("; // each shape may have associated metadata string[] metadataNames = shape.GetMetadataNames(); if (metadataNames != null) { foreach (string metadataName in metadataNames) { // escape single quotes to avoid insert issues colString = shape.GetMetadata(metadataName); int curPosn = 0; while (colString.IndexOf("'", curPosn) > -1) { curPosn = colString.IndexOf("'", curPosn); colString = colString.Substring(0, curPosn) + "'" + colString.Substring(curPosn); curPosn += 2; } nonqueryCommand.CommandText += "'" + colString + "', "; } } else { Console.WriteLine("No metadata available."); return; } // cast shape based on the type switch (shape.Type) { case ShapeType.Point: // a point is just a single x/y point ShapePoint shapePoint = shape as ShapePoint; geom = "geometry::STGeomFromText('POINT(" + shapePoint.Point.X + " " + shapePoint.Point.Y + ")', " + srid + "))"; // Console.WriteLine("Point={0},{1}", shapePoint.Point.X, shapePoint.Point.Y); break; case ShapeType.Polygon: // a polygon contains one or more parts - each part is a list of points which // are clockwise for boundaries and anti-clockwise for holes // see http://www.esri.com/library/whitepapers/pdfs/shapefile.pdf ShapePolygon shapePolygon = shape as ShapePolygon; if (shapePolygon.Parts.Count == 1) geom = "geometry::STGeomFromText('POLYGON"; else geom = "geometry::STMPolyFromText('MULTIPOLYGON("; foreach (PointD[] part in shapePolygon.Parts) { // Console.WriteLine("Polygon part:"); geom += "(("; foreach (PointD point in part) geom += point.X + " " + point.Y +", "; // Remove the last comma geom = geom.Substring(0, geom.Length - 2); geom += ")), "; } // Remove the last comma geom = geom.Substring(0, geom.Length - 2); if (shapePolygon.Parts.Count > 1) geom += ")"; geom += "'," + srid + "))"; break; default: // and so on for other types... break; } nonqueryCommand.CommandText += geom; int rows = nonqueryCommand.ExecuteNonQuery(); } } catch (Exception ex) { Console.WriteLine(ex.Message); Console.WriteLine(); return; } Console.WriteLine("Done"); Console.WriteLine();That is it. You should be able to run the application and use it to load your data.
Here is a link to the completed project with source code.




<Return to section navigation list>
MarketPlace DataMarket and OData
Sublight Labs (@SublightLabs) announced Sublight implements OData service in a 6/12/2011 post:
Sublight now implements The Open Data (OData) web protocol for querying data from Sublight database directly from your web browser.
Here are some query examples:
API/odata.svc/SubtitlesAPI/odata.svc/Subtitles?$filter=startswith(Title, 'American Beauty') eq trueAPI/odata.svc/Subtitles?$filter=Publisher eq 'macofaco'API/odata.svc/Subtitles?$filter=PublishedUTC gt datetime'2011-06-01' and PublishedUTC lt datetime'2011-06-02'This will enable easy integration of Sublight services from other clients.
 Sublight is a free Windows application with a user interface, which allows you to download subtitles for your movies easily and quickly.
Sublight is a free Windows application with a user interface, which allows you to download subtitles for your movies easily and quickly.
Podnova.com reviewed Kreuger Systems, Inc.’s OData Browser in a 6/12/2011 post:
OData Browser
- Free
- Publisher: Krueger Systems, Inc.
- Home page: kruegersystems.com
- Latest version: 1.0
Description
OData Browser enables you to query and browse any OData source. Whether you're a developer or an uber geek who wants access to raw data, this app is for you.
It comes with the following sources already configured:
- Netflix - A huge database of movies and TV shows
- Open Government Initiative - Access to tons of data published by various US government branches
- Vancouver Data Service - Huge database that lists everything from parking lots to drinking fountains
- Nerd Dinner - A social site to meet other nerds
- Stack Overflow, Super User, and Server Fault - Expert answers for your IT needs
Anything else! If you use Sharepoint 2010, IBM WebSphere, Microsoft Azure, then you can use this app to browse that data.
The app features:
- Support for data relationship following
- Built-in map if any of the data specifies a longitude and latitude
- Built-in browser to navigate URLs and view HTML
- Query editor that lists all properties for feeds
Use this app to query your own data or to learn about OData.
There is a vast amount of data available today and data is now being collected and stored at a rate never seen before. Much, if not most, of this data however is locked into specific applications or formats and difficult to access or to integrate into new uses. The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today.
Screenshots








<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Eugenio Pace (@eugenio_pace) announced availability of the release candidate of Claims Identity Guide–Hands On Labs in a 6/13/2011 post:
Training content based on our guides has been as popular as the content itself. You can now download the “Release Candidate” for labs corresponding to the new guide.
The labs are more than just a mirror of the guide. We took the opportunity of adding a few things that complement and extend what is explained in the book. A notable addition is using ADFS v2.
The guide talks a lot about “using ADFS for a production environment”, but all samples shipped use a “simulated STS” (this is of course than for convenience and to minimize the dependencies on your dev environment). Well, now you will have a chance of using experimenting and learning about ADFS v2.
But there’s more of course.
Here’s the compete “Table of Contents”. Feedback always very welcome.
Lab 1
Exercise 1: Making Applications Claims-aware. In this exercise you will modify two Adatum web applications (a-Order and a-Expense) that currently use forms-based authentication to make them claims-aware, and to provide the user with a single sign-on (SSO) experience.
Exercise 2: Enabling Single Sign-Out. In this exercise you will add code to the applications so that users logging out of one are automatically logged out of the other.
Exercise 3: Using WIF Session Mode. In this exercise you will modify the applications to change the behavior of the WIF modules so that token information is stored in the session instead of the authentication cookie.
Lab 2
Exercise 1: Federating Adatum and Litware. In this exercise, you will modify the Adatum a-Order web application to trust the Adatum federation provider, and configure the Adatum federation provider to trust both the Adatum and Litware identity providers.
Exercise 2: Home Realm Discovery. In this exercise, you will modify the a-Order web application to send a whr parameter to the federation provider. You will then modify the Adatum federation provider to use the value of the whr parameter to determine the identity provider the user should authenticate with.
Exercise 3: Federation with ADFS. In this optional exercise, you will replace the custom Adatum federation provider with ADFS.
Lab 3
Exercise 1: Adding ACS as a Trusted Issuer. In this exercise you will start with a version of the a-Order application similar to that you used in previous labs, and modify it to use Windows Azure AppFabric Access Control Service (ACS) as the trusted issuer and identity provider in addition to the Adatum federation provider and simulated issuer.
Exercise 2: Adding the Facebook Identity Provider and Home Realm Discovery. In this exercise you will add Facebook as an identity provider to your ACS namespace. This illustrates how, by taking advantage of ACS, you can easily change the options a user has for authentication when using your applications; without requiring any modification of the application or of your own local token issuer or federation provider.
Exercise 3: Adding a Custom OpenID Identity Provider. In this exercise you will use the ACS Management API to programmatically add a relying party application that uses the OpenID identity provider.
Exercise 4: Replacing the Adatum Federation Provider with ADFS. In this optional additional exercise you will replace the existing Adatum federation provider with an ADFS instance, and configure this to use ACS as a token issuer and identity provider.
Lab 4
Exercise 1: Using Claims with SOAP Web Services. In this exercise, you will modify the SOAP-based Adatum a-Order web service to use claims. You will also modify the desktop client application to work with the new version of the service.
Exercise 2: Using Claims with REST Web Services. In this exercise, you will modify the REST-based Adatum a-Order web service to use claims. You will also modify the desktop client application to work with the new version of the service.
Exercise 3: Federation with ADFS. In this optional exercise, you will replace the custom Adatum federation provider with ADFS.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Abu Obeida Bakhach (@abuobeida) posted Announcing WCF Express Interop Bindings to the Windows Azure AppFabric Team Blog on 6/13/2011:
Today, we are pleased to further simplify the WS-* interop challenge by providing the WCF Express Interop Bindings Extension for Visual Studio 2010, launched at wcf.codeplex.com. This new extension enables WCF developers to avoid much of the formerly needed guesswork to configure a WCF service to connect with the top Java platforms via the known WS-* specifications, by creating custom interoperable WCF bindings on demand, building on settings described in the white papers above.
Until now, the bindings in WCF provided a wide range of interoperable and non-interoperable options to establish connections. Developers burned the midnight oil too many times, perusing various reports from WS-I, or huddling in online forums figuring out the required interop settings. Java web services, mostly relying on policy based configurations, proved tricky for .NET WCF developers to configure their services and clients. .NET Developers needed to configure security settings, algorithms, policies in various bindings elements in an often time consuming manner, resulting in a challenge larger than necessary.
We took the first step towards simplifying interop with Java by releasing a series of white papers outlining settings required for security interop with IBM WebSphere and Oracle WebLogic and Metro, along with various guidance on interop with Java datatypes and SAP.
Today, we are taking the second step in releasing this extension that simplifies interop with the leading java middleware platforms:
Simply select your platform of choice, the options of Reliable Messaging, Security, MTOM, and the extension generates a complete WCF service, configured with a dynamically generated binding that works right out of the with box with the Java platform of your choice. This extension is the best interop solution for the novice and intermediate WCF developer. Advanced developers can further customize the pre-defined settings that we have tested with the leading Java platforms for their own use. What required hours and days before is now doable in mere minutes!
The extension is provided as an open source project at wcf.codeplex.com amongst other projects by the WCF Team. Download the source code and the binary here.
We will be publishing a series of walkthroughs on codeplex helping you establish quick interoperable services. The first of which is here.
Feel free to customize this extension for your own enterprise use, and share your feedback on how this might evolve to cover more scenarios.

Abu Obeida is an Interoperability Program Manager.
The Windows Azure Team recommended that you Check Out New Windows Azure Jump Start Video Series in a 6/13/2011 post:
Course segments include:
- Session 01: Windows Azure Overview
- Session 02: Introduction to Compute
- Session 03: Windows Azure Lifecycle, Part 1
- Session 04: Windows Azure Lifecycle, Part 2
- Session 05: Windows Azure Storage, Part 1
- Session 06: Windows Azure Storage, Part 2
- Session 07: Introduction to SQL Azure
- Session 08: Windows Azure Diagnostics
- Session 09: Windows Azure Security, Part 1
- Session 10: Windows Azure Security, Part 2
- Session 11: Scalability, Caching & Elasticity, Part 1
- Session 12: Scalability, Caching & Elasticity, Part 2, and Q&A
Get access the content for this class, as well as student files and demo code at the Windows Azure Born To Learn Forum.
Options for gaining access to Windows Azure for the labs:
- Free Windows Azure Platform 30-day pass for US-based students (use promo code: MSL001)
- MSDN Subscribers: http://msdn.microsoft.com/subscriptions/ee461076.aspx
- Free access for CPLS, Partners: https://partner.microsoft.com/40118760
- Options for all others: http://www.microsoft.com/windowsazure/offers
<Return to section navigation list>
Visual Studio LightSwitch
Michael Washington (@ADefWebserver) posted Integrating Visual Studio LightSwitch Application Into An Existing Website using IFrames to The Code Project on 6/12/2011:
Live example:
http://lightswitchhelpwebsite.com/Demos/ThingsForSale.aspx
For an introductory article on LightSwitch, see:
Note: You must have Visual Studio Professional, or higher, to perform all the steps in this tutorial
You can download Visual Studio LightSwitch from this link:
http://www.microsoft.com/visualstudio/en-us/lightswitch
Putting Multiple LightSwitch Applications Into Your Website
Microsoft Visual Studio LightSwitch suffers from what I call the "full screen limitation". LightSwitch wants to fill the entire screen, and it wants to manage the roles and users. This is fine if you only have one application, however in many situations, you want a LightSwitch application to be part of a group of applications in a single portal. You want all applications to share the same users, roles and database.
Unlike the article Online Ordering, that describes a normal "LightSwitch only" deployment, this article will explore the techniques used to deploy a LightSwitch application inside a ASP.NET application that contains other applications. In this article, DotNetNuke will be used, however, everything here can be used in any ASP.NET application.
The key to integrating LightSwitch into an ASP.NET application, is to use IFrames.
The Requirements
In this example, we will create an application that meets the following requirements:
- Allow Registered Users (the Posters), the ability to create Posts of things they have for sale, without the need to post their email address
- Allow Anonymous Users (the Buyers) the ability to see the Posts without requiring them to have the Silverlight plug-in installed
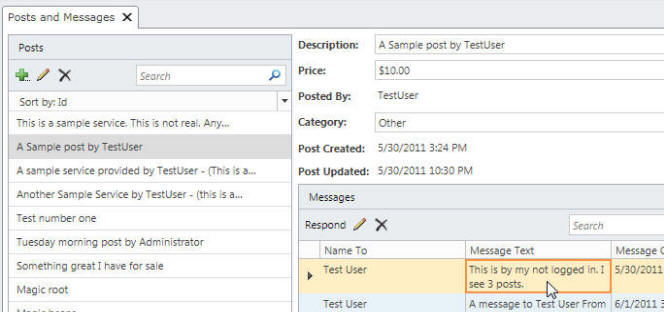
- Allow the Buyers the ability to respond to a Post, and automatically email the Poster
- Allow the Poster the ability to view and respond to all communications sorted by Post
- Allow Administrators the ability to edit all data
This may not be considered a large application, but it would take a few days effort. With LightSwitch, you can create the entire application in about an hour.
Walk-Thru Of The 'Things For Sale' Application
You can try out the live Things For Sale application at this link: http://lightswitchhelpwebsite.com/Demos/ThingsForSale.aspx
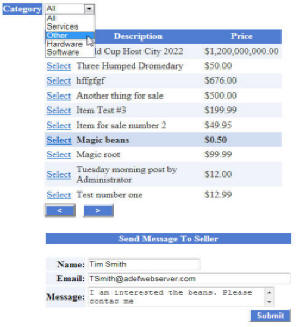
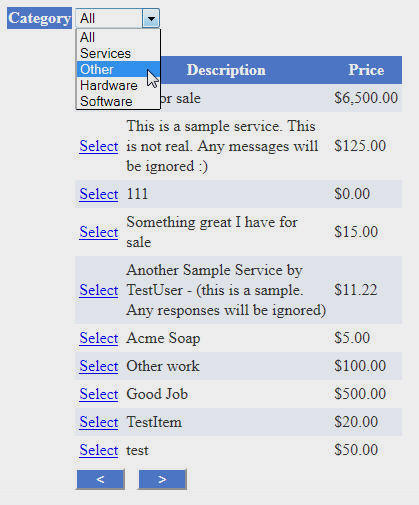
When you are not logged-in, you will see a list of Posts that you can browse.
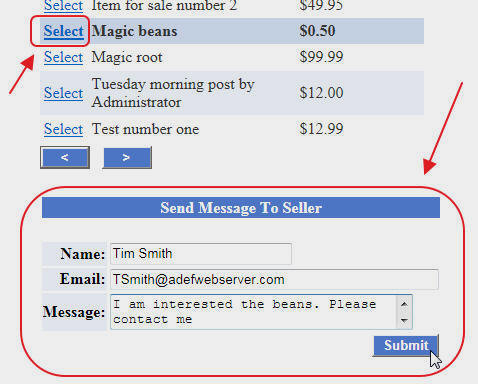
You can click on a Post to send the Poster a message.
When you log in, you will have the ability to create Posts, and to see any Messages related to a Post (you will be emailed when a new Message is created for one of your Posts).
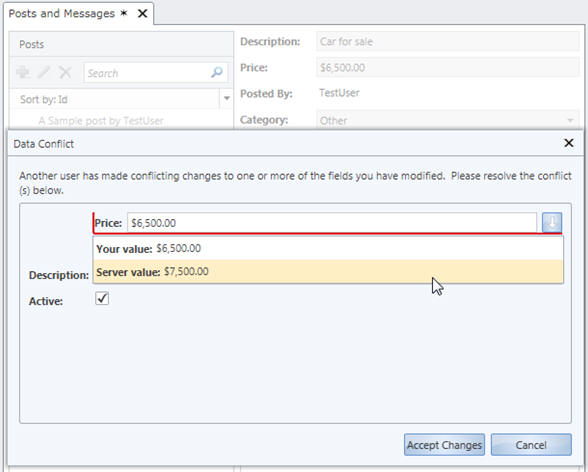
Also note, that there are a lot of other features such as Concurrency Checking and Automatic Ellipses that LightSwitch implements automatically.

Michael continues with detailed (and lengthy) Creating the Application and related sections.
Read more.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Lori MacVittie (@lmacvittie) asserted The dynamic data center of the future, enabled by IT as a Service, is stateless in an introduction to her IT as a Service: A Stateless Infrastructure Architecture Model article of 6/13/2011 for F5’s DevCentral blog:
One of the core concepts associated with SOA – and one that failed to really take hold, unfortunately – was the ability to bind, i.e. invoke, a service at run-time. WSDL was designed to loosely couple services to clients, whether they were systems, applications or users, in a way that was dynamic. The information contained in the WSDL provided everything necessary to interface with a service on-demand without requiring hard-coded integration techniques used in the past. The theory was you’d find an appropriate service, hopefully in a registry (UDDI-based), grab the WSDL, set up the call, and then invoke the service. In this way, the service could “migrate” because its location and invocation specific meta-data was in the WSDL, not hard-coded in the client, and the client could “reconfigure”, as it were, on the fly.
There are myriad reasons why this failed to really take hold (notably that IT culture inhibited the enforcement of a strong and consistent governance strategy) but the idea was and remains sound. The goal of a “stateless” architecture, as it were, remains a key characteristic of what is increasingly being called IT as a Service – or “private” cloud computing .
TODAY: STATEFUL INFRASTRUCTURE ARCHITECTURE
The reason the concept of a “stateless” infrastructure architecture is so vital to a successful IT as a Service initiative is the volatility inherent in both the application and network infrastructure needed to support such an agile ecosystem. IP addresses, often used to bypass the latency induced by resolution of host names at run-time from DNS calls, tightly couple systems together – including network services. Routing and layer 3 switching use IP addresses to create a virtual topology of the architecture and ensure the flow of data from one component to the next, based on policy or pre-determine routes as meets the needs of the IT organization. It is those policies that in many cases can be eliminated; replaced with a more service-oriented approach that provisions resources on-demand, in real-time. This eliminates the “state” of an application architecture by removing delivery dependencies on myriad policies hard-coded throughout the network.
Policies are inexorably tied to configurations, which are the infrastructure equivalent of state in the infrastructure architecture.
Because of the reliance on IP addresses imposed by the very nature of network and Internet architectural design, we’ll likely never reach full independence from IP addresses. But we can move closer to a “stateless” run-time infrastructure architecture inside the data center by considering those policies that can be eliminated and instead invoked at run-time. Not only would such an architecture remove the tight coupling between policies and infrastructure, but also between applications and the infrastructure tasked with delivering them. In this way, applications could more easily be migrated across environments, because they are not tightly bound to the networking and security policies deployed on infrastructure components across the data center.
The pre-positioning of policies across the infrastructure requires codifying topological and architectural meta-data in a configuration. That configuration requires management; it requires resources on the infrastructure – storage and memory – while the device is active. It is an extra step in the operational process of deploying, migrating and generally managing an application. It is “state” and it can be reduced – though not eliminated – in such a way as to make the run-time environment, at least, stateless and thus more motile.
TOMORROW: STATELESS INFRASTRUCTURE ARCHITECTURE
What’s needed to move from a state-dependent infrastructure architecture to one that is more stateless is to start viewing infrastructure functions as services. Services can be invoked, they are loosely coupled, they are independent of solution and product. Much in the same way that stateless application architectures address the problems associated with persistence and impede real-time migration of applications across disparate environments, so too does stateless infrastructure architectures address the same issues inherent in policy-based networking – policy persistence.
While standardized APIs and common meta-data models can alleviate much of the pain associated with migration of architectures between environments, they still assume the existence of specific types of components (unless, of course, a truly service-oriented model in which services, not product functions, are encapsulated). Such a model extends the coupling between components and in fact can “break” if said service does not exist. Conversely, a stateless architecture assumes nothing; it does not assume the existence of any specific component but merely indicates the need for a particular service as part of the application session flow that can be fulfilled by any appropriate infrastructure providing such a service. This allows the provider more flexibility as they can implement the service without exposing the underlying implementation – exactly as a service-oriented architecture intended. It further allows providers – and customers – to move fluidly between implementations without concern as only the service need exist. The difficulty is determining what services can be de-coupled from infrastructure components and invoked on-demand, at run-time. This is not just an application concern, it becomes an infrastructure component concern, as well, as each component in the flow might invoke an upstream – or downstream – service depending on the context of the request or response being processed.
Assuming that such services exist and can be invoked dynamically through a component and implementation-agnostic mechanism, it is then possible to eliminate many of the pre-positioned, hard-coded policies across the infrastructure and instead invoke them dynamically. Doing so reduces the configuration management required to maintain such policies, as well as eliminating complexity in the provisioning process which must, necessarily, include policy configuration across the infrastructure in a well-established and integrated enterprise-class architecture.
Assuming as well that providers have implemented support for similar services, one can begin to see the migratory issues are more easily redressed and the complications caused by needed to pre-provision services and address policy persistence during migration mostly eliminated.
SERVICE-ORIENTED THINKING
One way of accomplishing such a major transformation in the data center – from policy to service-oriented architecture – is to shift our thinking from functions to services. It is not necessarily efficient to simply transplant a software service-oriented approach to infrastructure because the demands on performance and aversion to latency makes a dynamic, run-time binding to services unappealing. It also requires a radical change in infrastructure architecture by adding the components and services necessary to support such a model – registries and the ability of infrastructure components to take advantage of them. An in-line, transparent invocation method for infrastructure services offers the same flexibility and motility for applications and infrastructure without imposing performance or additional dependency constraints on implementers.
But to achieve a stateless infrastructure architectural model, one must first shift their thinking from functions to services and begin to visualize a data center in which application requests and responses communicate the need for particular downstream and upstream services with them, rather than completely in hard-coded policies stored in component configurations. It is unlikely that in the near-term we can completely eliminate the need for hard-coded configuration, we’re just no where near that level of dynamism and may never be. But for many services – particularly those associated with run-time delivery of applications, we can achieve the stateless architecture necessary to realize a more mobile and dynamic data center.


Todd Bishop asked New York Times casts Microsoft as a relic, but is it really the Kodak of PCs? in a 6/12/2011 article for Geek Wire:
There’s plenty to criticize Microsoft about these days. The company has fallen behind Apple in mobile phones and tablets. It’s trailing Google in phones and search. Its stock has been stuck for years. But a New York Times editorial this weekend paints an incomplete picture by implying that Microsoft hasn’t been able to expand beyond the personal computer.
The editorial — titled “Remember Microsoft?” — is pegged to hedge fund manager David Einhorn’s recent call for Microsoft CEO Steve Ballmer to step aside.
An excerpt from the New York Times piece …
Eastman Kodak, the fifth-biggest company in the S.& P. 500 in 1975, was almost destroyed by digital cameras and is no longer in the index. General Motors, fifth biggest in 1985, was hobbled by rivals that could make more fuel efficient cars. Microsoft still rules the PC desktop. But that will matter less and less as users migrate to tablets and more computing takes place in “the cloud.”
But more glaring is the NYT editorial board’s lack of recognition (or awareness?) of Microsoft’s strength in computer servers and game consoles — actual successes for the company in key technology markets beyond the PC desktop. Windows Server had a 75% share of worldwide server shipments in the first quarter, and Xbox 360 has been atop the U.S. console industry for 10 of the past 11 months, outpacing industry veterans Nintendo and Sony in the domestic market.
Together, the Server & Tools and Entertainment & Devices units were responsible for more than a third of Microsoft’s record annual revenue of $62 billion last year.
The competitive threats and internal challenges facing Microsoft are serious. Windows Phone is struggling out of the gate. A new, tablet-friendly Windows interface isn’t expected on the market until next year. Recent trends in PC shipments should be especially troubling for the company, showing the iPad taking a toll on traditional Windows sales. Microsoft still moves too slowly on many fronts, and critical scrutiny of the company’s long-term prospects is as warranted as ever.
But let’s start with an accurate understanding of where Microsoft stands. And it’s not next to Kodak.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Wes Yanaga (pictured below) recommended Combining Public and Private Clouds into Useful Hybrids in a 6/13/2011 post to the US ISV Evangelism blog:
Watch David Chou’s TechEd session about the widely discussed “hybrid” approach – solutions spanning from on-premise into the cloud. This session offers a discussion of how usage of multiple cloud solutions enables large enterprises to be successful in adopting cloud computing, as well as a review of challenges that go with it.
Please visit Microsoft Tech Ed Registration site and create a free account
Then visit this link to see the video and download the slides
Getting Started with Windows Azure
See the Getting Started with Windows Azure site for links to videos, developer training kit, software developer kit and more. Get free developer tools too.
See Tips on How to Earn the ‘Powered by Windows Azure’ Logo.
For free technical help in your Windows Azure applications, join Microsoft Platform Ready.
Learn What Other ISVs Are Doing on Windows Azure
For other videos about independent software vendors (ISVs) on Windows Azure, see:
- Accumulus Makes Subscription Billing Easy for Windows Azure
- Azure Email-Enables Lists, Low-Cost Storage for SharePoint
- Crowd-Sourcing Public Sector App for Windows Phone, Azure<
- Food Buster Game Achieves Scalability with Windows Azure
- BI Solutions Join On-Premises To Windows Azure Using Star Analytics Command Center
- NewsGator Moves 3 Million Blog Posts Per Day on Azure
- How Quark Promote Hosts Multiple Tenants on Windows Azure

No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Wes Yanaga posted Security Talk Series–Cloud Computing to the US ISV Evangelism blog on 6/11/2011:
- MSDN Video: Case Study Interview with Quest Software
- MSDN Video: Quest Software's Azure Services
- MSDN Video: Security in Provisioning and Billing Solutions for Windows Azure Platform
- MSDN Video: Updated: Windows Azure Platform Security Essentials: Module 2 – Identity Access Management
- MSDN Video: Updated: Windows Azure Platform Security Essentials: Module 3 – Storage Access
- MSDN Video: Updated: Windows Azure Platform Security Essentials: Module 4 – Secure Development
- MSDN Video: Windows Azure Platform Security Essentials: Module 1 - Security Architecture
- MSDN Video: Windows Azure Platform Security Essentials: Module 2 – Identity Access Management
- MSDN Video: Windows Azure Platform Security Essentials: Module 3 – Storage Access
- MSDN Video: Windows Azure Platform Security Essentials: Module 4 – Secure Development
- TechNet Video: Cloud Security Panel Interview at TechEd NA 2010
- TechNet Video: Data Security in Azure (Part 1 of 2)
- TechNet Video: Data Security in Azure (Part 2 of 2)
- TechNet Video: Microsoft Private Cloud Security Overview
- TechNet Video: Security Talk: Security Considerations in Quest Software’s Windows Azure On-Demand Solutions
- TechNet Video: Security Talk: Windows Azure Security - A Peek Under the Hood
- TechNet Video: Updated: Windows Azure Platform Security Essentials for Business Decision Makers
- TechNet Video: Updated: Windows Azure Platform Security Essentials for Technical Decision Makers
- TechNet Video: What about Security in the Cloud?
- TechNet Video: White Board Session: Online Services Security and Compliance: Microsoft’s Compliance Framework for Online Services
- TechNet Video: Windows Azure Platform Security Essentials for Business Decision Makers
- TechNet Video: Windows Azure Platform Security Essentials: Module 5 - Secure Networking using Windows Azure Connect
- TechNet Video: Windows Azure Platform Security Essentials: Module 6 – Windows Azure Role Security
About Windows Azure
The Windows Azure platform is commercially available in 41 countries and enables developers to build, host and scale applications in Microsoft datacenters located around the world. It includes Windows Azure, which offers developers an Internet-scale hosting environment with a runtime execution environment for managed code, and SQL Azure, which is a highly available and scalable cloud database service built on SQL Server technologies. Developers can use existing skills with Visual Studio, .NET, Java, PHP and Ruby to quickly build solutions, with no need to buy servers or set up a dedicated infrastructure, and with automated service management to help protect against hardware failure and downtime associated with platform maintenance.
Getting Started with Windows Azure
- See the Getting Started with Windows Azure site for links to videos, developer training kit, software developer kit and more. Get free developer tools too.
- See Tips on How to Earn the ‘Powered by Windows Azure’ Logo.
- For free technical help in your Windows Azure applications, join Microsoft Platform Ready.
Learn What Other ISVs Are Doing on Windows Azure
For other videos about independent software vendors (ISVs) on Windows Azure, see:
- Accumulus Makes Subscription Billing Easy for Windows Azure
- Azure Email-Enables Lists, Low-Cost Storage for SharePoint
- Crowd-Sourcing Public Sector App for Windows Phone, Azure<
- Food Buster Game Achieves Scalability with Windows Azure
- BI Solutions Join On-Premises To Windows Azure Using Star Analytics Command Center
- NewsGator Moves 3 Million Blog Posts Per Day on Azure
- How Quark Promote Hosts Multiple Tenants on Windows Azure
<Return to section navigation list>
Cloud Computing Events
Brian Loesgen reported Camp Time in San Diego, Cloud Camp and Code Camp this week in a 6/13/2011 post:
We have two camps happening this week in San Diego (and they’re pretty much guaranteed to be “bear free”, unlike this).
I will be speaking at both of them.
Tuesday June 14th, Cloud Camp, Hyatt Regency Mission Bay, 6:00PM, details here. This is the second Cloud Camp in San Diego this year, the first one was extremely well attended, and there was great feedback. This is an “un-conference” with no pre-designated session agenda, but, it’s a safe bet I’ll be in an Azure session.
Then, this weekend (Saturday and Sunday) brings the annual Code Camp. It will be held at UCSD at 9600 N. Torrey Pines Rd., La Jolla, CA 92037, and you can register for Code Camp here.
I will be doing three sessions (follow the links for details and registration):
- Windows Azure Overview
- Windows Azure- What’s in it for Startups and ISVs?
- Windows Azure Architectural Patterns
The good news is that my three sessions are all on Saturday, in the order shown, in room 111. The bad news is that this means I’ll be speaking for 4 hours non-stop, so there will be Red Bull involved and perhaps throat lozenges. But, if you’ve been wondering about Azure, or using it, this is a great way to get a solid dose of it!
<Return to section navigation list>
Other Cloud Computing Platforms and Services
My Choosing a cloud data store for Big Data article for SearchCloudComputing.com of 6/13/2011 claimed “Choosing the optimum infrastructure for your organization's Big Data isn't a walk in the park” and discussed NoSQL, NOSQL, AnySQL, and NewSQL data stores:
Incumbent giants and hopeful startups are spearheading advanced technologies for managing petabytes of data erupting from a new generation of social computing and data analysis applications, commonly called Big Data. One of the most vexing problems facing enterprise IT management wanting to handle Big Data is filtering a growing cloud data store taxonomy.
Choosing the optimum infrastructure for your organization's Big Data isn't a walk in the park.
The NoSQL category gained initial developer mindshare with the first no:sql(east) conference in October 2009, which might be better named no:rdm or no:rel for "no (to the) relational data model." The NoSQL moniker today applies primarily to open source approaches to high-availability, massively scalable and fully durable data stores that don't involve the traditional relational model and Structured Query Language. NoSQL fundamentalists, such as Heroku's Adam Wiggins, contend that "SQL databases are fundamentally non-scalable, and there is no magical pixie dust that we, or anyone, can sprinkle on them to suddenly make them scale."
Virtually all discussions of relational database scalability involve interpretation of Brewer's Theorem, first expounded in Eric Brewer's "Toward Robust Distributed Systems" keynote speech of July 19, 2000 at the ACM Symposium about the Principles of Distributed Computing (PODC). Brewer posited that there are three desirable features of distributed systems, such as Web services, which include databases:
- Consistency represents the C in the ACID test of "atomicity, consistency, isolation and durability" for data store transactions.
- Availability means a fast response to every query and update while maintaining consistency.
- Partition tolerance refers to the ability of the system to remain available and consistent despite failures of individual sub-components such as servers and disk drives.
Brewer's Theorem, which was proven formally in 2002, states that it is impossible to achieve all three of these features simultaneously in the asynchronous network model typified by stateless Web services. It's most common for NoSQL proponents to settle for the "eventual consistency" exhibited by Amazon.com's Dynamo data store.
The following four classifications define most NoSQL data store genres:
- Key-Value/Tuple Stores include Windows Azure table storage, Amazon Dynamo, Dynomite, Project Voldemort, Membase, Riak, Redis, BerkeleyDB and MemcacheDB.
- Wide-Column/Column Families Store members are Apache Hadoop/HBase, Apache Cassandra, Amazon SimpleDB, Hypertable, Cloudata and Cloudera.
- Document Stores include CouchDB, MongoDB and RavenDB.
- Graph Databases emphasize relationships between entities, which are difficult to model with relational databases. Neo4j, Dryad, FlockDB, HyperGraphDB, AllegroGraph and Sones are more interesting examples.
Enterprise-level IT managers commonly rank the viability of NoSQL databases by the breadth of their commercial usage, sponsorship or both by high-visibility Web properties or sponsors, such as Amazon Web Services (SimpleDB and Amazon RDS), Apache Foundation (Hadoop, CouchDB and Cassandra), LinkedIn (Project Voldemort), Microsoft (Windows Azure, SQL Azure and Dryad), Twitter (Hadoop, Cassandra, Redis and FlockDB) and Yahoo! (Hadoop/Pig). Hadoop/HBase and its MapReduce programming model are probably the most widely used NoSQL members in mid-2011; Yahoo! is reportedly planning to spin off its seasoned Hadoop development team into a standalone commercial venture.
Dryad's place in the cloud data store world
The Dryad distributed graph database has been under development by Microsoft Research for the past six years or so. According to Microsoft Research, Dryad "provides a general, flexible execution layer" that uses a "dataflow graph as the computation model. It completely subsumes other computation frameworks, such as Google's map-reduce or the relational algebra. Moreover, Dryad handles job creation and management, resource management, job monitoring and visualization, fault tolerance, re-execution, scheduling, and accounting."DryadLINQ is "is a simple, powerful, and elegant programming environment for writing large-scale data parallel applications running on large PC clusters. DryadLINQ combines two important pieces of Microsoft technology: the Dryad distributed execution engine and the .NET Language Integrated Query (LINQ)."
In May 2011, blogger Mary Jo Foley reported that "HPC 2008 R2 SP2 is the slated delivery vehicle for Dryad, Microsoft's closest competitor to Google MapReduce and Apache Hadoop." …
The article continues with these topics:
- SQL and NoSQL: The same?
- A look at NewSQL databases
Read the entire article here. See also my SQL or No SQL for Big Data in the Cloud? article of 5/1/2011 for Visual Studio Magazine’s May 2011 issue.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
Udayan Bannerjee described Amazon EC2 – How much has it changed in last 18 months? in 6/13/2011 post:
Is there a significant change in the pricing? The answer is almost none – there slight decrease in the charge of higher end EC2 instances. You can see the summary status as on January 2010.
So, what has actually changed?
Free instance – 750 hours of micro instance with 10GB of storage free and 15GB bandwidth
- Micro instance – at quarter the rate of small instance (USD 0.02 per hour for Linux)
- More availability zone – Singapore & Tokyo added in addition to US(N. Virginia, N. California) and EU(Ireland)
- RDS for Oracle – charges are 50% more than MySQL for smaller instances and 30% more for larger instances
- Cluster computing instances – available for USD 1.6 to 2.1 per hour, only at US – Virginia
- Elastic Map Reduce – uses Hadoop and EC2 instance type of your choice. In addition to the EC2 instance price and the storage price, you also need to pay for Elastic Map Reduce for each instance, which can be between USD 0.015 per hour to 0.42 per hour.
- Virtual Private Cloud – lets you provision a private, isolated section where you can launch AWS resources in a virtual network that you define.
- PaaS offering – using Java & Tomcat stack
- More manageability options – like cloud watch, auto scaling, etc.
Free instance
Micro Instance
Micro Instance 613 MB of memory, up to 2 ECUs (for short periodic bursts), EBS storage only, 32-bit or 64-bit platform.
More Manageability Option
Auto Scaling – It allows you to scale your capacity up or down automatically according to conditions you define. For example, you can ensure that the number of Amazon EC2 instances you’re using increases during demand spikes and decreases during demand lulls. It is enabled by Amazon CloudWatch and available at no additional charge beyond Amazon CloudWatch fees.
CloudWatch – It provides monitoring for AWS cloud resources and the applications customers run on AWS. Developers and system administrators can use it to collect metrics and monitors resources. Basic Monitoring metrics (at five-minute frequency) for Amazon EC2 instances are free of charge, as are all metrics for Amazon EBS volumes, Elastic Load Balancers, and Amazon RDS DB instances. New and existing customers also receive 10 metrics (applicable to Detailed Monitoring for Amazon EC2 instances or Custom Metrics), 10 alarms, and 1 million API requests each month at no additional charge. Detailed monitoring is charged.


Intel Corp. offered more details on its Hybrid Cloud Program and AppUp services for small business in a June 2011 update to its Web site:
Offer your small business customers cloud-like flexibility, with the confidence of onsite hardware.
The Intel® Hybrid Cloud program, featuring the Intel AppUp℠ Small Business Service, enables you to provide customers with server software and services on a pay-as-you-go basis, along with the stability and confidence of on-premises hardware. You get a turnkey, remotely manageable cloud solution and your customers receive the benefits of cloud-based services combined with the responsiveness and security of local hardware.
The Intel AppUp Small Business Service, an innovative software delivery mechanism and catalog of small business applications, runs on the Intel Hybrid Cloud platform, which features a scalable, pre-configured server with robust remote management capabilities. The Intel Hybrid Cloud platform also includes the Intel Hybrid Cloud software, server, and management portal. The Intel AppUp Small Business Service enables you to deliver cloud-like benefits with flexibility, confidence and a better user experience for your small business customers.
As you would expect the hybrid system proposed local server hardware with a cloud connection to apps select from an Intel catalog. I’m not sanguine about the prospects for this ISV product.
James Urquhart (@jamesurquhart) claimed Apple's iCloud rep[resent]s best vision yet for consumers in a 6/13/2011 post to his Wisdom of Clouds blog:

Apple's much-anticipated announcement of cloud services for its OS X and iOS device portfolio was as sleek and integrated as most everything the Cupertino, Calif., company does.
While there has been extensive coverage of last week's announcement, I think the most important aspect of the announcement hasn't been given its due.
Apple now owns the beginnings of what will likely be the world's leading integrated consumer cloud portfolio.
Let's be clear. I'm not claiming Apple is the only consumer cloud service or that it will have the dominant share of cloud services overall. But Apple has the first end-to-end cloud experience from a consumer perspective. And--as is core to Apple's strategy--by owning every level of the user experience, the company can only make it tougher on the rest of the consumer computing market for the next several years.
"We're going to demote the PC and the Mac to just be a device," CEO Steve Jobs said. With those words, Jobs highlighted the reason iCloud will work. Computers are still difficult for many consumers, though the experience on both the PC and Mac side have gotten much better in the last 10 years. However, the rapid adoption of the smartphone--especially the iPhone--by consumers showed all of us that nothing needs to be difficult.
What seems to have occurred to Apple is that one of the primary reasons desktops and laptops have remained difficult to maintain is that they are the center of the computing universe for the consumer. Everything has had to be stored and executed there. So any required software must be installed by the consumer, and any required data must be acquired or generated by the consumer.
As we all know by now, the cloud combined with the mobile application model is a powerful disruptor. Want an app on your phone? Click "Buy It." Want access to data on multiple devices? Use online services to create, store, and analyze that data.
What Apple did was integrate the most common content-related functions directly into the phone, with no need to find, evaluate, or maintain the cloud services behind them beyond the initial configuration. It's just easy--remote control easy.
Now imagine Apple expandx that work to include video processing (with iCloud behind it), Garage Band track sharing (through iCloud), even a social network built around the consumer content stored in iCloud. All of it integrated in very intelligent ways, and all of it--or at least a "starter" version of all of it--included in the price of the phone.
Believe me, I'm not a fan of the "Steve Jobs will decide when and how you get your content--and for how much" scenario. (I've stopped buying from Apple for that reason.) CNET editor Dong Ngo put this discomfort in terms that I think will resonate with many digital media consumers:
The second side effect is the loss of control. As iCloud is integrated into apps and devices, that might mean users will not have control over it, and may even not be able to opt out. If you store your purchased digital content in Apple's iCloud storage space, that could mean the company has control over what you can view. It's unclear if you can even upload your own content, ripped music from your CDs or music purchased from other services for example, and store it in Apple's iCloud. Judging from the way iTunes syncs contents with devices, it's a safe guess that the iCloud service will offer users much less control over it than other existing cloud services.
However, I absolutely admire the user experience that Apple continues to drive. As Pip Coburn, author of "The Change Function," might say, it both solves a "crisis" (content sharing between devices) and has an extremely low total cost of adoption--a magic formula that will probably put aside concerns about control for many, many people.
To be sure, I think iCloud should be a wake-up call to the two companies that should have delivered these services by now, Microsoft and Google. It also validates a market in which Amazon.com has quietly been building up an impressive portfolio.
iCloud also gives us another reason to wonder whether any company can out-innovate Apple in the consumer computing arena...or the consumer cloud.
Antony Falco (@antonyfalco) claimed It's Time to Drop the "F" Bomb - or "Lies, Damn Lies, and NoSQL." in a 5/11/2011 post to the Basho blog (missed when posted):
I’m on a plane to Goto Copenhagen from our electric post-Kill-Dash-Nine Board meeting in Washington, DC and, afterwards, an intense client meeting. I went to watch Pete Sheldon, our new Director of Sales, and Justin Sheehy at work. I finally had a chance to sit and study a proposal for the Basho product roadmap for the next year. This roadmap is both breathtakingly ambitious and oddly incremental, quotidian even.
In the next year we will solve problems endemic to distributed systems – groundbreaking work of the sort careers are surely made — and yet at the same time, these problems seem incremental and iterative; part of an ongoing process of small improvements. They seem both astounding and inevitable.
This led me to an interesting insight — doing this is not easy.
What we are doing is like digging a canal through bedrock. We are hacking away at hard problems — problems others encountered and, either died trying or, mopping their brows with their handkerchiefs, threw down their shovels and went shopping. A lot of cool companies are hacking away, too, so it is not like we are alone, but the honorable and the diligent are not what this post is about.
This post is about the ugly truth I have to call out.
To put it bluntly, if you are claiming the architectural challenges presented by applications with high write loads spread across multiple data centers are easy, you are lying. You do not, as Theo Schlossnagle remarked recently to us, “respect the problem.” You must respect the problem or you disrespect the necessary tradeoffs. And if you disrespect the tradeoffs, you disrespect your user. And if you disrespect your user, you are, inevitably, a liar. You say this is easy. You promise free lunches. You guarantee things that turn out to be impossible. You lie.
What our technology generation is attempting is really hard. There is no easy button. You can’t play fast and loose with the laws of physics or hand-wave around critical durability issues. You can sell this stuff to your venture capitalist, but we’re not buying it.
Immutable laws are not marketing. And therefore, marketing can’t release you from the bonds of immutable laws. You can’t solve the intractable problems of distributed systems so eloquently summarized with three letters – C-A-P – by Google’s cloud architect (and Basho Board member) Dr. Eric Brewer (a man both lauded and whose full impact on our world has not yet been reckoned), with specious claims about downloads and full consistency.
To wit:
- Memory is not storage.
- Trading the RDBMS world for uptime is hard. There are no half-steps. No transitional phases.
- The geometry of a spinning disk matters for your app. You can’t escape this.
- Your hardware RAID controller is not perfect. It screws things up and needs to be debugged.
- Replication between two data centers is hard, let alone replication between three or 15 data centers.
- Easily adding nodes to a cluster under load impacts performance for a period determined by the amount of data stored on the existing nodes and the load on the system…and the kind of servers you are using…and a dozen other things. It looks easy in the beginning.
These are all sensible limitations. Like the speed of light or the poor quality of network television, these are universal constants. The point is: tradeoffs can’t be solved by marketing.
To be sure, there are faster databases than Riak. But do they ship with default settings optimized for speed or optimized for safety? We ache to be faster. We push ourselves to be faster. We tune and optimize and push. But we will never cross the line to lose data. While it is always tempting to set our defaults to fast instead of safe, we won’t do it. We will sacrifice speed to protect your data. In fact, if you prefer speed to preserving data, don’t use Riak. We tell the truth even if it means losing users. We will not lie.
Which is why others who do it make me ball my fists, score my palms, and look for a heavy bag to punch. Lying about what you can do – and spreading lies about other approaches – is a blatant attempt to replace the sacrifice of hard-core engineering and ops with fear, uncertainty, and doubt – FUD.
People who claim they are “winning NoSQL” with FUD are damaging our collective chance to effect a long-overdue change to the way data is stored and distributed. This opportunity is nothing short of a quantum shift in the the quality of your life if you are in development, operations, or are a founder who lives and dies by the minute-to-minute performance of your brainchild/application.
The FUD-spreaders are destroying this opportunity with their lies. They are polluting the well by focusing on false marketing – on being the loud idiot drunk – instead of solving the problem. They can screw this up with their failure. It is time for us to demand they drop the FUD – drop the “F” bomb – and stop lying about what they can do. Just tell the truth, like Basho does — admit this is a hard problem and that hardcore engineering is the answer. In fact, they should do the honorable thing and quit the field if they are not ready to invest in the work needed to solve this problem.
If we, collectively, the developer and sysadmin community running the infrastructure of the world economy, allow people to replace engineering with marketing lies, to trade coffee mugs for countless hours of debugging, and in doing so, to destroy the reputation of a new class of data storage systems before they have had a chance to gain a foothold in the technology world, we all lose.
There are many reasons why the FUD spreaders persist.
There are the smart folks who throw our hands up and cynically say that liars are by their nature better marketers. But marketing need not be lies, cynically accepted. Basho pushed hard to find a marketing VP – Martin Schneider – hungry to master the technology. He respects the problem.
Then there are some of us who are too busy keeping projects or businesses afloat to really dig into the facts. But we sense that we are being lied to, and so we detach, saying this is all FUD. This can’t help us. Tragically, we miss the opportunity to make a big change
Most of us simply want to trust other developers and will believe claims that seem too good to be true. If we do this, we are in a small but serious way saying that our hard-won operational wisdom is meaningless, that anyone who has deployed a production application or contributed to an open-source project has no standing to challenge the loud-mouth making claims that up-time is easy.
Up-time is not easy. Sleeping through the night without something failing is a blessing. Do not – do not – let VCs and marketers mess up our opportunity to take weekends off and sleep through the night when we are on call. The database technologies of 1980 (and their modern apologists in NoSQL) should not shape the lives of technologists in 2011.
In Conclusion…
In the briefest terms, Basho won’t betray this revolution because we keep learning big lessons from our small mistakes. We are our harshest critics.
We will deliver a series of releases that allow you to tune for the entire spectrum of CAP tradeoffs – strong consistency to strong partition tolerance – while making clear the tradeoffs and costs. At the same time Riak will provide plugins for Memcache, secondary indices, and also a significant departure from existing concepts of MapReduce that allows for flexible, simple, yet massively distributed computation, and much more user-friendly error reporting and logging. (Everyone reading this understands why that last item merits inclusion on any list of great aspirations – usability can damn or drive a project.)
We will deliver these major innovations, improvements, and enhancements, and they will be hard for us and our community to build. And it will take time for us to explain it to people. And you will find bugs. And it will work better a year after it ships than it does on day one.
But we will never lie to you.
We call on others to please drop the FUD, to acknowledge the truth about the challenges we all face running today’s infrastructure, and to join us in changing the world for the better.
Colleen Taylor asked Is Apple tapping Amazon and Microsoft to boost iCloud? in a 6/10/2011 post to the Giga Om blog:
Apple entered into the cloud services arena with a bang with the launch of iCloud at the Worldwide Developer Conference in San Francisco this week. But according to a recent post at the InfiniteApple blog, Apple appears may be getting a little help from its frenemies in getting iCloud off the ground.
An anonymous tipster sent a series of screenshots to InfiniteApple earlier this week. The screenshots (embedded at the bottom of this post) purportedly show the HTTP traffic logged when an image is sent through Apple’s new iMessage service. The Infinite Loop post says the data may indicate that iCloud is utilizing Amazon’s cloud storage system S3 and Microsoft’s Azure cloud service to assist in delivering the message.
Does this mean that the photos of the new 500,000 square foot data center Steve Jobs showed off during the WWDC keynote are just a front? Not necessarily. We ran the screenshots by three networking and cloud experts at major companies. All three said that the screenshots did not conclusively show how iCloud was utilizing the Amazon and Microsoft technologies, if at all.
Two sources said that the log could simply show that the image sent over iMessage was itself initially hosted on Azure or Amazon. A third source said Apple may be using Azure and AWS for content delivery network (CDN) purposes. That would mean that the files are ultimately hosted on Apple servers, but Apple is caching copies of some data on strategically placed CDN servers run by Azure and Amazon’s CloudFront to help speed up delivery. In other words, Apple could be leveraging cloud services from Amazon and Microsoft for short-term iCloud caching to boost speed and reliability — not because its own servers are incapable of handling the content.
Utilizing CDNs is a very common practice even at the highest levels, the third source added. Apple itself has a history of using CDNs, but mostly Akamai and Limelight to help serve media content such as iTunes. If anything, the big scandal here is not that Apple is using third-party cloud services to run iCloud, but that it’s opted to use Microsoft and Amazon’s offerings instead of its longtime partners.
But again, we ultimately did not turn up any slam-dunk verdict on exactly how iCloud is using AWS and Azure, if at all. If you have any insight, please chime in via the comments. And to learn more about clouds, CDNs and networking, please attend our Structure 2011 conference on June 22 and 23 in San Francisco.
Screenshots sourced from InfiniteApple.net
Related content from GigaOM Pro (subscription req’d):




<Return to section navigation list>

















0 comments:
Post a Comment