Windows Azure and Cloud Computing Posts for 4/2/2011+
| A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework 4+
- Windows Azure Infrastructur and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Chris Ismael posted The Windows Azure Table – IKEA analogy to the Innovative Singapore blog on 4/3/2011:
A few days ago I gave an overview presentation of Windows Azure to some BizSpark startups. One of the questions that I got asked often during and after the presentation was why they would bother with a Windows Azure Table when there’s a SQL Azure available.
I admit that after the presentation I felt that I have not explained this quite well too. Unfortunately, I don’t think it can be explained in one shot, but rather as series of explanations that eventually build up to one “Aha” moment. So I hope this post will provide helpful information in understanding the existence of Azure Tables and why it’s cheap. In a later post, we will touch on some uses for Azure Tables.
Why an Azure Table is cheaper
To start off, let me point out an interesting characteristic of Tables that will tie all this together: a very simplistic structure.

(Picture from Bing)
When I think of Azure Tables, I always remember IKEA’s brochure explaining how they can sell furniture cheaper than anyone else. (If you need a primer on what IKEA is, here’s a Wikipedia link). They refer to it as “flat-packing” and it is the way they design the furniture pieces so that more can be produced and transported. Assembling the furniture is also generally the responsibility of the buyer, not IKEA’s. As most of you know, when you buy stuff from IKEA, the parts are neatly arranged in the slimmest way possible in a box, and has easy to follow instructions to assemble the parts.
In a very similar way, Tables are much like IKEA’s flat-packing process. It is structured in a very simplistic manner so that it’s easier to transport and cheaper to produce.
Easier To Transport/Move
You might be asking right now, where are we supposed to move the Tables, and why would I do that anyway? Well, first and foremost, “moving” the table is handled by Microsoft for you (explanation coming in a bit). So you need not worry about that part. The interesting question is why Microsoft would need to “move” Tables.
By now (hopefully), you should understand that one of the benefits of cloud computing is being able to provide a platform that will stand up to hardware breakdown. This is done through the concept of having redundant “machines”, which is achieved by having several virtualized instances of your application i.e., I can have 3 virtualized instances of my application so if 1 goes down, the my users can still access my application because their requests are load- balanced to the other 2 instances/machines. Thus we can achieve 100% uptime (in ideal cases).
Now going back to the IKEA analogy, try to imagine IKEA running a sale for $1 dinner table. They’d be swarmed with hungry buyers (high load). Fortunately for IKEA, they have designed and flat-packed each dinner table into slim boxes, so they can stack more of it and sell/deliver more if they need to.

In the same way for Tables, Microsoft is replicating your Tables so that it can stand up to high load. If one of your tables goes down (a defective IKEA dinner table that needs to be replaced), Microsoft re-routes requests to the duplicate copies while it tries to start another instance a.k.a “move” so that you maintain a redundant setup. Microsoft can do this very quickly and easily because Tables, unlike a relational database (say SQL Azure), have a simpler structure that is easier to replicate across several machines. There are no table relationships to worry about (each IKEA dinner table will have its own assembling instructions and tools), so an Azure table could be sitting in one machine, and another table on another, and they don’t have to worry about each other. User “queries” will just be re-routed to wherever Microsoft “moved” the Tables to, and it will independently satisfy the user requests.
In a relational database, it’s much more complex to “move” tables because you’d have to bring along all the other tables related to the table you’re querying (assuming you have relationships across them) to make sure that it works on one machine. Each machine in the redundant set-up would need to have all related tables in one machine for the “JOINS” to work. This would take a lot of time and processing power. Time and power cost money. In Windows Azure Tables, a JOIN statement doesn’t apply, because it was designed that way to make each table independent and easier/faster to replicate. The term for this is a denormalized table.
Now you might be asking, are you saying SQL Azure doesn’t have redundancy? Absolutely not! Redundancy is also built-in for SQL Azure. But as I said, the less-complex structure of an Azure Table makes it much cheaper.
Cheaper To Produce
Now you know why it’s like this: (Pay-As-You-Go Pricing from http://www.microsoft.com/windowsazure/pricing/).
Azure Tables
- $0.15 per GB stored per month
- $0.01 per 10,000 storage transactions
SQL Azure
- Web Edition
- $9.99 per database up to 1GB per month
- $49.95 per database up to 5GB per month
- Business Edition
- $99.99 per database up to 10GB per month
- $199.98 per database up to 20GB per month
- $299.97 per database up to 30GB per month
- $399.96 per database up to 40GB per month
- $499.95 per database up to 50GB per month
The IKEA dinner table is cheap because IKEA designed it with simplicity in mind, it doesn’t take up too much space when moving it, and they let the buyer assemble the table themselves. The non-IKEA dinner table is expensive because it’s already an assembled piece. Moving it around the factory and delivering it to your house is much more hassle than moving a flat box. Also, IKEA can respond to demand much faster because the design of their tables allows them to easily move it around and produce them faster.
At this point I hope one thing is obvious, that to get the benefit out of a cloud computing platform for data storage in terms of standing up to unpredictable load, replication is a necessity. And the easiest, fastest, and cheapest way for Microsoft to replicate your data is to employ a simple structure. Hence, Azure Tables were provided as an option.
In a later post we will explore in more detail how queries can be much faster in Windows Azure Tables, and sample scenarios for using Tables.


I’m still waiting for Windows Azure Table storage to support secondary indexes.
Keith Bauer published Comparing REST API’s: Windows Azure Queue Service vs. Amazon Simple Queue Service (SQS) on 3/30/2011:
A recent customer engagement prompted me to share details regarding a comparison of the REST API’s used to manage the Windows Azure Queue Service and the Amazon Simple Queue Service (SQS). As expected, these services both provide similar types of message queuing functionality for their respective platforms: create queues, delete queues, send messages, retrieve messages, etc… However, what is not typically expected is the fact that Amazon’s SQS service does not support a REST API. As stated in the 2009-02-01 SQS migration guide, “the REST API is not available”.
This wasn’t always the case. In fact, the Amazon SQS used to have a REST interface which provided all of the basic message queuing services. This was originally provided in their SQS API version 2006-04-01 as well as in their SQS API version 2007-05-01, both of which have been superseded by a newer API which no longer provides a REST interface. Figure 1 below illustrates how the REST API’s used to compare to one another.

Figure 1 – REST API for Common Queue Service Operations
Implications
Contemplating the differences between these REST API’s is now a moot point. If you are steadfast on using a REST architectural style for your cloud-based message queuing needs then the Windows Azure Queue Service should provide what you are looking for. However, to be fair, even though Amazon’s SQS REST API is no longer available, they do support other methods which use simple HTTP/HTTPS requests and provide all of the same functionality as their previous REST API. One of the methods used to manage SQS today is the SQS Query API, which uses both GET and POST methods. Although similar to REST in many ways, the SQS Query API does not adhere to all of the guidelines of a REST architecture style, as defined in the often referenced dissertation by Roy Thomas Fielding. Optionally, you can leverage the SOAP protocol for making SOAP requests and calling SQS service actions. This, however, is only supported by Amazon over an HTTPS connection.
Note
The Amazon SQS REST API is no longer available. SQS service management is provided via the SQS Query API, or SQS SOAP API.
Some of you may be wondering, if the SQS Query API uses HTTP/HTTPs coupled with GET and POST methods, then why is this not REST? Well, for starters, the SQS Query API does not represent a resource as a URI. This violates one of the requirements for calling an API a REST API. However, if you are in the camp of people which accept various levels of REST (i.e. level 0, 1, 2, 3), then according to the Richardson Maturity Model as a way of measuring the restful maturity of a service, the SQS Query API can arguably be considered a Level 0 REST interface. Although, Roy Thomas Fielding, the individual known for coining the REST term, would likely not call anything a REST API until at least a Level 3 interface has been achieved.
Summary
The purpose of this article is not to debate whether REST is good or bad, or to determine if a service which supports a REST API is any better or worse than the other. Rather, this should provide clarity that the Windows Azure Queue Service leverages a REST API, while Amazon’s Simple Queue Service (SQS) leverages the SQS Query API, as well as a SOAP API. Hopefully this brief synopsis has provided some bit of useful insight with the necessary background for better understanding how these common cloud-based message queuing solutions are managed.
Resources and References
- Windows Azure “Queue Service API” article in the MSDN Library
- Amazon Simple Queue Service “Developer Guide – API Version 2006-04-01” PDF
- Amazon Simple Queue Service “Developer Guide – API Version 2007-05-01” PDF
- Amazon Simple Queue Service “Developer Guide – API Version 2008-01-01” PDF
- Amazon Simple Queue Service “Developer Guide – API Version 2009-02-01” Online
- Dissertation by Roy Thomas Fielding
- Richardson Maturity Model
<Return to section navigation list>
SQL Azure Database and Reporting
Mauricio Rojas described Windows Azure Migration: Database Migration, Post 1 in a 4/2/2011 post:
When you are doing an azure migration, one of the first thing you must do is
collect all the information you can about your database.Also at some point in your migration process you might consider between migration to SQL Azure or Azure Storage or Azure Tables.
Make all the appropriate decisions you need to collect at least basic data like:
- Database Size
- Table Size
- Row Size
- User Defined Types or any other code that depends on the CLR
- Extended Properties
Database Size
You can use a script like this to collect some general information:
create table #spaceused( databasename varchar(255), size varchar(255), owner varchar(255), dbid int, created varchar(255), status varchar(255), level int) insert #spaceused (databasename , size,owner,dbid,created,status, level) exec sp_helpdb select * from #spaceused for xml raw drop table #spaceusedWhen you run this script you will get an XML like:
<row databasename="master" size=" 33.69 MB" owner="sa" dbid="1" created="Apr 8 2003" status="Status=ONLINE, ..." level="90"/> <row databasename="msdb" size=" 50.50 MB" owner="sa" dbid="4" created="Oct 14 2005" status="Status=ONLINE, ..." level="90"/> <row databasename="mycooldb" size=" 180.94 MB" owner="sa" dbid="89" created="Apr 22 2010" status="Status=ONLINE, ..." level="90"/> <row databasename="cooldb" size=" 10.49 MB" owner="sa" dbid="53" created="Jul 22 2010" status="Status=ONLINE, ..." level="90"/> <row databasename="tempdb" size=" 398.44 MB" owner="sa" dbid="2" created="Feb 16 2011" status="Status=ONLINE, ..." level="90"/>And yes I know there are several other scripts that can give you more detailed information about your database
but this one answers simple questions likeDoes my database fits in SQL Azure?
Which is an appropriate SQL Azure DB Size?Also remember that SQL Azure is based on SQL Server 2008 (level 100).
- 80 = SQL Server 2000
- 90 = SQL Server 2005
- 100 = SQL Server 2008
If you are migrating from an older database (level 80 or 90) it might be necessary to upgrade first.
This post might be helpful: http://blog.scalabilityexperts.com/2008/01/28/upgrade-sql-server-2000-to-2005-or-2008/
Table Size
Table size is also important.There great script for that:
http://vyaskn.tripod.com/sp_show_biggest_tables.htm
If you plan to migrate to Azure Storage there are certain constraints. For example consider looking at the number of columns:
You can use these scripts: http://www.novicksoftware.com/udfofweek/vol2/t-sql-udf-vol-2-num-27-udf_tbl_colcounttab.htm (I just had to change the alter for create)
Row Size
I found this on a forum (thanks to Lee Dice and Michael Lee)
DECLARE @sql VARCHAR (8000) , @tablename VARCHAR (255) , @delim VARCHAR (3) , @q CHAR (1) SELECT @tablename = '{table name}' , @q = CHAR (39) SELECT @delim = '' , @sql = 'SELECT ' SELECT @sql = @sql + @delim + 'ISNULL(DATALENGTH ([' + name + ']),0)' , @delim = ' + ' FROM syscolumns WHERE id = OBJECT_ID (@tablename) ORDER BY colid SELECT @sql = @sql + ' rowlength' + ' FROM [' + @tablename + ']' , @sql = 'SELECT MAX (rowlength)' + ' FROM (' + @sql + ') rowlengths' PRINT @sql EXEC (@sql)Remember to change the {table name} for the name of the table you need
User Defined Types or any other code that depends on the CLR
Just look at your db scripts at determine if there are any CREATE TYPE statements with the assembly keyword.
Also determine if CLR is enabled with a query like:select * from sys.configurations where name = 'clr enabled'
If this query has a column value = 1 then it is enabled.
Extended Properties
Look for calls to sp_addextendedproperty dropextendedproperty OBJECTPROPERTY and sys.extended_properties in your scripts.
Mark Kromer (@mssqldude) posted More on Cloud BI @ SQL Mag BI Blog on 4/2/2011:
I’ve started a new series on building Cloud BI with Microsoft technologies at the SQL Server BI Blog, starting with ETL using SSIS to move data from traditional on-premises SQL Server to SQL Azure databases, serving as a data mart: http://bit.ly/hggUeT.
Steve Yi posted a Recap of CloudConnect, and the Future of Data to the SQL Azure Team blog on 4/1/2011:
On Wednesday March 9th, I had the opportunity to talk at Cloud Connect about cloud computing, the Windows Azure platform - and I also took some time to talk about what the public cloud is along with some growing trends that will affect and shape the future of the cloud. If you're interested, you can find the deck here. In our discussions with customers and partners, there are two things that are quickly converging currently separate conversations about cloud, web, data, and mobile devices:
- Public Cloud and Platform -As-A-Service (PaaS) abstract away the complexity of infrastructure maintenance, still providing high-availability, failover, and scalability, and are open, flexible, and heterogeneous.
- The future of the web is about data - sharing it to multiple user experiences, extending it beyond the silos of the office, and deriving new insights by easily joining your data with external sources of information.
The unique opportunities that public cloud and platform-as-a-service (PaaS) bring to developers and businesses is the ability to focus specifically user experience and features that benefit users, rather than focusing on non-functional requirements like failover and high-availability. While critical to the operation of a system, users don't necessarily experience any of those benefits tangibly, except of course, if the system goes down.
A great example of a solution using the full potential of public cloud and PaaS is Eye On Earth. As a service of the European Environment Agency (EEA), it collects data from 6,000 monitoring stations across the European Union, coordinating efforts across all 32 member countries to present a centralized visualization of air and water quality to 600 million citizens. Eye On Earth also connects 600 partner organizations across research institutes, universities, ministries and agencies.
In a strictly on-premises world, solutions like this would never exist. The capital expenditures necessary to serve and maintain and infrastructure to serve 600 million people is daunting, with much of it lying idle much of the time. Additionally, with the matrix of different agencies, ministries, sharing the cost of such a solution would have been a nightmare. The economics of the cloud made this feasible. There's also the challenge of collecting and aggregating data efficiently across 6,000 remote monitoring stations. Cloud databases such as SQL Azure now make this possible. You can read more here, and see a video about it here.
With the growing reach of mobile devices everywhere, the web has evolved to more than just a mere browser experience - it is a heterogeneous mix of browser, smartphone, tablet applications and the application marketplaces. Users demand applications that are more agile, robust and accessible via the web. The cloud provides the perfect platform to step into delivering again this demand by users. In this new demand generation frontier, it is critical for developers to create hybrid applications and premises aware systems that are synchronized and provide multi-form factor user experiences.
Shifting gears here, to my second assertion - that the future of the web is about data. The past dozen or so years have seen the explosion of the web, and over the past few years that's evolved to include user experiences on mobile devices and tablets. What's quickly evolving is the necessity of extending data beyond user experiences - now to developers, content partners, and available via web APIs to compose n-number of variable new user experiences. Some interesting numbers to note:
- “LinkedIn Founder: Web 3.0 Will Be About Data: Mashable Mar 30 2011 - http://mashable.com/2011/03/30/reid-hoffman-data/
- “Smartphone shipments surpass PCs” (2010 Q4): Financial Times Feb 08 2011 - http://www.ft.com/cms/s/2/d96e3bd8-33ca-11e0-b1ed-00144feabdc0.html#axzz1DV7zJ5nj
- “Twitter Reveals: 75% of Our Traffic is via API (3 billion calls per day): Programmable Web Apr 15 2010 - http://blog.programmableweb.com/2010/04/15/twitter-reveals-75-of-our-traffic-is-via-api-3-billion-calls-per-day/
- Proliferation of Web APIs fuel the popularity of a web service…increasingly the API is the service: Wired Mar 08 2011 - http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/
The web has evolved to more than just a browser experience; it's a heterogeneous mix of browser, smartphone, tablet applications and app-markets. The cloud has an important role to play in this evolution, by easily extending data from on-premises data sources and synchronizing it to the cloud through technologies like SQL Azure Data Sync and making it available to everyone, every developer, and every device.
Through initiatives we're taking to support open web data protocols such as OData, embracing this world of cloud data is available now, where one cloud service can power multiple experiences across web, device, and plug into existing social media and geospatial user experiences.
Industry-wide, this evolution will undoubtedly take time. It's exciting to be participating in this change, watching the transition happen, and watching how public cloud and PaaS are connecting data across the on-premises world to the web.



Jonathan Gao posted SQL Azure SQL Authentication to the TechNet Wiki on 3/31/2011:
SQL Azure supports only SQL Server authentication. Windows authentication (integrated security) is not supported. You must provide credentials every time when you connect to SQL Azure.
You can use Transact-SQL to administrate additional users and logins using either Database Manager for SQL Azure or SQL Server Management Studio 2008 R2. Both tools will list the users and logins associated with the databases; however, at this time it does not provide a graphical user interface for creating the users and logins.
Note: The current version of SQL Azure supports only one Account Administrator and one Service administrator account.
In this Article
- The master database
- Creating logins
- Creating users
- Configuring user permissions
- Deleting users and logins
The Master Database
A SQL Azure Server is a logical group of databases. Databases associated with one server Azsre server may spread on different physical computers at the Microsoft data center. You must perform server-level administration for all of the database on the master database. For example, the master database keeps track of the logins. You must connect to the master database to create and drop logins.
Creating Logins
Logins are server wide login and password pairs, where the login has the samepassword across all databases. You must be connected to the master database on SQL Azure with the administrative login to execute the CREATE LOGIN command. Some of the common SQL Server logins can be used like sa, Admin, root. For a complete list, see Managing Databases and Logins in SQL Azure at http://msdn.microsoft.com/en-us/library/ee336235.aspx.
--create a login named "login1"
CREATE LOGIN login1 WITH password='pass@word1';
--list logins. You must run this statement separately from the CREATE LOGIN statement
SELECT * FROM sys.sql_logins;Note: SQL Azure does not allow the USE Transact-SQL statement, which means that you cannot create a single script to execute both the CREATE LOGIN and CREATE USER statements, since those statements need to be executed on different databases.
Creating Users
Users are created per database and are associated with logins. You must be connected to the database in where you want to create the user. In most cases, this is not the master database.
--create a user named "user1"
CREATE USER user1 FROM LOGIN login1;
Configuring User Permissions
Just creating the user does not give them permissions to the database. You have to grant them access. For a full list of roles, see Database-level roles
--give user1 read-only permissions to the database via the db-datareader role
EXEC sp_addrolemember 'db_datareader', 'user1';
Deleting Users and Logins
Fortunately, SQL Server Management Studio 2008 R2 does allow you to delete users and logins. To do this traverse the Object Explorer tree and find the Security node, right click on the user or login and choose Delete. You can also use the DROP LOGIN and the DROP USER statements.
See Also
<Return to section navigation list>
MarketPlace DataMarket and OData
Steve Marx (@smarx) and Wade Wegner (@WadeWegner) produced a 00:34:14 Cloud Cover Episode 42 - The Meaning of Life, the Universe, and Everything (also DataMarket) Channel9 video segment on 4/1/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show @CloudCoverShow.
In this episode, Christian "Littleguru" Liensberger joins Steve and Wade as they discuss the Windows Azure Marketplace DataMarket. Christian explains the purpose of DataMarket, shows an ASP.NET MVC 3 demo, and shares some tips and tricks.
Also covered in this show:
- Channel 9: Getting Started with the Windows Azure Toolkit for Windows Phone 7
- Database Import/Export in SQL Azure
- Windows Azure sessions at MIX11 posted
- The Rock, Paper, Azure! challenge (also on YouTube)
- Updated MSDN documentation: Steps to Set-up Invoicing
If you’re looking to try out the Windows Azure Platform free for 30-days—without using a credit card—try the Windows Azure Pass with promo code "CloudCover".
Arlo Belshee started Geospatial Question: Common Operations and More Scenarios threads on the OData Mailing List on 4/1/2011. These topics might interest current and potential users of SQL Server’s geometry and geography data types.
Jason Birch’s (@jasonbirch) response describes two common operations and mentions many geospatial data formats. His Geospatial Ramblings blog is here.
OData is one of GeoREST’s Example Format Outputs; simple configuration data is here.
The thread archive and mailing list signup link is here. Arlo is a senior program manager on Microsoft’s OData team.
Marshall Kirkpatrick reported Data.gov & 7 Other Sites to Shut Down After Budgets Cut in a 3/31/2011 post to the ReadWriteWeb blog:
Two years ago the incoming Obama administration launched a number of ambitious websites, most notably Data.gov, that were dedicated to offering public and government data to the outside world. The stated intention was to foster transparency and offer a platform for the development of new software and services. It appears those experiments may be over for now.
Today the Sunlight Foundation and Federal News Radio reported that the public projects Data.gov, USASpending.gov, Apps.gov/now, IT Dashboard and paymentaccuracy.gov as well as a number of internal government sites including Performance.gov, FedSpace and many of the efforts related the FEDRamp cloud computing cybersecurity effort would be taken offline in coming weeks due to budget cuts by Congress. Perhaps things like electronic government, software platforms and public accountability were just fads, anyway.
Update:. We're hearing from several places that there's a potentially viable effort to save these sites and organizations. Here is one perspective on that and you can also see the Sunlight Foundation's Save the Data petition. See also Alex Howard's in-depth reporting on this news published on Friday.
<Return to section navigation list>
Windows Azure AppFabric: Access Control, WIF and Service Bus
Valery Mizonov explained Windows Azure AppFabric Service Bus and Location Virtualization without the Loch Ness Monster in a 3/31/2011 post to the AppFabric CAT blog:
The following post is not about my trip to Scottish Highlands in 2005 even though it was fun having been able to spend a few days with “Nessie”. I just thought I would share some observations from a recent customer engagement that attracted no legendary monsters whatsoever. Instead, it has proved the value of a monstrous capability that exists in the Windows Azure AppFabric Service Bus and this prompted me to spend a few minutes documenting some key insights.
Problem Space
Software components in modern solutions can present the degree of multi-scale complexity in their behavior. Tracing the source of a calculation error in the algorithmic trading module that is part of a highly distributed trading system is not trivial. It’s just hard, although the word “hard” doesn’t appear to be sufficiently reflective to express the true pain. Luckily, modern developer tools have rapidly caught up and made it easier to debug and troubleshoot puzzling code on a developer machine. Next, there was “It works on my box!” theme. Again, the developer tools did not lose this battle and started offering remote debugging capabilities. Next, there was “The Cloud” theme. And this is where it has landed itself on the developer’s desk, this time with no painkiller pills.
Problem Definition
Let’s just say, a service in my solution was developed by a group of ex-rocket scientists and mostly due to its over-engineered complexity, it’s not subject to any forms of troubleshooting except attaching a debugger and stepping through the source code. Let’s also say that for some obvious reasons, my goal is to be able to run this service outside my local, easily accessible networking infrastructure. I even may take the liberty to say that I want my service to be running on the Cloud, and not where the bunch of brain surgeons code geeks prescribe me to host it. In essence, I’m running into a problem that can be generically abstracted as follows:
If things go wrong, how do I step into and debug my technically challenging cloud service component?
In principle, all I would like to know is how I go about troubleshooting a complex issue in my live cloud-based multi-layer heavily distributed solution, ideally using the same tools and techniques which I rely on in the traditional on-premises world. I want it to be as easy as practically possible, as painless as humanly possible and as effective as clinically possible while ensuring that I’m not going against physics of time travel and not losing my brand as being a Rock Star problem solver. The last statement doesn’t apply to me personally though.
Problem Refined
Enough with abstractions, let’s now face the reality. Deploying and setting up remote debugging service, opening up ports and keeping fingers crossed is one way. It works in theory but fails to derive the expected results in practice. The remote debugging components in Visual Studio require both TCP and UDP ports to be traversable through a firewall, and I’m confident that it is going to be a tough dialog with the networking team trying to convince them to patch the firewall solely for remote debugging.
The other way would be to bring the faulty service into my on-premises environment where I can enjoy having the luxury of diagnostic tools to help facilitate the root cause analysis. Note that this service is just a small needle in the end-to-end architecture. It is barely survivable without the entire landscape of other services, back-end systems, middleware components and so on.
This is exactly where Windows Azure AppFabric Service Bus steps in. In addition to providing the messaging infrastructure for secure service interaction across network boundaries, it comes with rich location virtualization capability making services agnostic with respect to their physical location. The AppFabric Service Bus maps service endpoints into the shared, hierarchical federated namespace model enabling the endpoints to be identifiable by a well-known URI that is accessible regardless of the endpoint’s location. The endpoint URI does not change if service is relocated outside its original hosting boundaries.
So, what is there for me? Simply put, there is an opportunity to have a complete flexibility as it pertains to placement of services in a complex, distributed solution architecture. Services that register their endpoints on the AppFabric Service Bus can be located anywhere where there is an Internet connection – in a Windows Azure data center, private hosting environment, a box in the server room, a Hyper-V VM running on a developer workstation, whatever have you.
The AppFabric Service Bus infrastructure takes the responsibility for performing all the heavy lifting associated with registering an endpoint in the federated naming system, efficiently routing traffic to its virtual address, reconfiguring the virtual address when service deployment topology or location changes. What is left for the developer is a decision as to where to re-locate a buggy service so that both its binaries and source code (or PDB files) can be effectively accessed to provide familiar, much-desired local debugging experience.
What Did We Really Learn?
In a complex distributed solution, software components can be present at many physical locations, not always living together under a single roof. Abstracting these locations through the means of location virtualization provides the foundation of building highly agile service interactions. This in turn enables the interacting participants to be moveable across geo boundaries without having to make anyone aware of a change.
The Windows Azure AppFabric Service Bus addresses the location virtualization requirement and makes it easier to connect location-independent services in a discoverable, secure and dynamic fashion. This capability is attributed to the ESB space and comes very handy regardless whether the end goal is as big and bold as “providing true loose coupling between services and their consumers” and as small and naïve as “bringing error-prone cloud-based solution components into a development box for surgery”.
Additional Resources/References
- “Service Bus Namespace Model” article in the MSDN Library.
- “A Developer’s Guide to Windows Azure AppFabric Service Bus“ whitepaper by Aaron Skonnard.
- “Add the ability to remote debug my application running in the cloud” ask on Windows Azure Feature Voting Forum.
Christian Weyer announced a new 3/31/2011 drop of the thinktecture IdentityServer on CodePlex:
Project Description
thinktecture IdentityServer is the follow-up project to the very popular StarterSTS. It's an easy to use security token service based on WIF, WCF and MVC 3.
Disclaimer
IdentityServer did not go through the same testing or quality assurance process as a "real" product like ADFS2 did. IdentityServer is also lacking all kinds of enterprisy features like configuration services, proxy support or operations integration. The main goal of IdentityServer is to give you a starting point for building non-trivial security token services. Furthermore the current code base is in early stages - if you like a more tested version of this,please use StarterSTS.
High level features
- Active and passive security token service
- Supports WS-Federation, WS-Trust, REST, SAML 1.1/2.0 and SWT tokens
- Supports username/password and client certificate authentication
- Defaults to standard ASP.NET membership, roles and profile infrastructure
- Control over security policy (SSL, encryption, SOAP security) without having to touch WIF/WCF configuration directly
- Automatic generation of WS-Federation metadata for federating with relying parties and other STSes
Intro Screencast: http://identity.thinktecture.com/download/identityserver/identityserverctp1.wmvMy Blog: http://www.leastprivilege.com
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Avkash Chauhan explained Windows Azure Commandlets installation Issues with Windows Azure SDK 1.4 and Windows 7 SP1 in a 4/3/2011 post:
Installing Windows Azure Cmdlets on Windows 7 SP1 OS based machine with Windows Azure SDK 1.4 could results following TWO errors:
1. You will get an error that installer is not Compatible with your OS (Windows 7 SP1).
2. You will get an error that a depend component Windows Azure SDK 1.3 is missing.
- You can download Windows Azure Cmdlets form the link below:
http://archive.msdn.microsoft.com/azurecmdlets/Release/ProjectReleases.aspx?ReleaseId=3912
- After it, please expand "WASM Cmdlets" installer (WASMCmdlets.Setup.exe) to a location in your machine. (i.e. C:\Azure\WASMCmdlets)
We will solve these two problems here:
To fix the installation problem related with Windows 7 SP1 please do the following:
1. Please browse C:\Azure\WASMCmdlets\setup folder and open Dependencies.dep file in notepad:
You will see the install script is searching for OS build numbers as below however the Windows 7 SP1 build number #7601 is missing:
<dependencies>
<os type="Vista;Server" buildNumber="6001;6002;6000;6100;6200;7100;7600">
2. Now Add Window 7 SP1 Build version 7601 at the end of the "os type" string as below:
<dependencies>
<os type="Vista;Server" buildNumber="6001;6002;6000;6100;6200;7100;7600;7601">
3. Save the file.
To fix the installation problem related with Windows Azure SDK 1.4 please do the following:
1. Please browse the C:\Azure\WASMCmdlets\setup\scripts\dependencies\check folder and open CheckAzureSDK.ps1 file in notepad:
You will see the install script is searching for Window Azure SDK version 1.3.11122.0038 as below:
$res1 = SearchUninstall -SearchFor 'Windows Azure SDK*' -SearchVersion '1.3.11122.0038' -UninstallKey 'HKLM:SOFTWARE\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall\';
$res2 = SearchUninstall -SearchFor 'Windows Azure SDK*' -SearchVersion '1.3.11122.0038' -UninstallKey 'HKLM:SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\';
2. Please replace the above value with 1.4.20227.1419 as below:
$res1 = SearchUninstall -SearchFor 'Windows Azure SDK*' -SearchVersion '1.4.20227.1419' -UninstallKey 'HKLM:SOFTWARE\Wow6432Node\Microsoft\Windows\CurrentVersion\Uninstall\';
$res2 = SearchUninstall -SearchFor 'Windows Azure SDK*' -SearchVersion '1.4.20227.1419' -UninstallKey 'HKLM:SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\';
3. Save the file.
The above two steps should [cure] your installation problem.
Avkash Chauhan described How to change your Windows Azure Deployment (Stage or Production) Cloud OS Version on 4/3/2011:
- Windows Server 2008 SP2
- Windows Server 2008 R2
If you decided to change Cloud OS version by any reason you can follow these steps:
1. Changing Cloud OS version to Windows Server 2008 R2
2. Changing Cloud OS version to Windows Server 2008 SP2


Tony Bishop (a.k.a., tbtechnet and tbtonsan, pictured below) described The Small, Small Business App on Azure that Shouts Big in a 4/1/2011 post to the TechNet blogs:
I was in an email thread today chatting about the apparent lack of cloud apps for the small, small business [1-10 persons]. Like magic, my friend Joe [Dwyer] emails me with a “Tony, just thought you’d like to see this” email.
Typical bright, smart yet humble Joe.
Wow.

http://www.onewaycommerce.com for more info.
So for those small businesses that worry about ways to not only setup an ecommerce site, but more importantly to share with the world all the great reviews about the business, OneWay Commerce just helped you.
Sales, marketing and campaigns all through Facebook, on Azure with QuickBooks. Auction and e-resellers watch out.
And, if there is any doubt that Azure is a game changer in terms of the lowest development costs and the fastest deployment cycles, just ask Joe [Dwyer].
Try Azure now. For free. 30-days. No credit card required. Promo code TBBLIF
http://www.windowsazurepass.com/?campid=A8A1D8FB-E224-E011-9DDE-001F29C8E9A8
Avkash Chauhan posted a List of Performance Counters for Windows Azure Web roles on 4/1/2011:
// .NET 3.5 counters @"\ASP.NET Apps v2.0.50727(__Total__)\Requests Total" @"\ASP.NET Apps v2.0.50727(__Total__)\Requests/Sec" @"\ASP.NET v2.0.50727\Requests Queued" @"\ASP.NET v2.0.50727\Requests Rejected" @"\ASP.NET v2.0.50727\Request Execution Time" @"\ASP.NET v2.0.50727\Requests Queued" // Latest .NET Counters (4.0) @"\ASP.NET Applications(__Total__)\Requests Total" @"\ASP.NET Applications(__Total__)\Requests/Sec" @"\ASP.NET\Requests Queued" @"\ASP.NET\Requests Rejected" @"\ASP.NET\Request Execution Time" @"\ASP.NET\Requests Disconnected" @"\ASP.NET v4.0.30319\Requests Current" @"\ASP.NET v4.0.30319\Request Wait Time" @"\ASP.NET v4.0.30319\Requests Queued" @"\ASP.NET v4.0.30319\Requests Rejected" @"\Processor(_Total)\% Processor Time" @"\Memory\Available MBytes @"\Memory\Committed Bytes" @"\TCPv4\Connections Established" @"\TCPv4\Segments Sent/sec" @""\TCPv4\Connection Failures" @""\TCPv4\Connections Reset" @"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Received/sec" @"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Sent/sec" @"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Total/sec" @"\Network Interface(*)\Bytes Received/sec" @"\Network Interface(*)\Bytes Sent/sec" @"\.NET CLR Memory(_Global_)\% Time in GC"
public class AddAzurePerformanceCounter { private IList<PerformanceCounterConfiguration> _perfCounters; public AddAzurePerformanceCounter (IList<PerformanceCounterConfiguration> counterCollection) { _perfCounters = counterCollection; } public void AddPerformanceCounter(string counterName, int minuteInterval) { PerformanceCounterConfiguration perfCounter = new PerformanceCounterConfiguration(); perfCounter.CounterSpecifier =counterName; perfCounter.SampleRate = System.TimeSpan.FromMinutes(minuteInterval); _perfCounters.Add(perfCounter); } }Add Performance Counters as Below:
AddAzurePerformanceCounter counters = new AddAzurePerformanceCounter(diagConfig.PerformanceCounters.DataSources); counters.AddPerformanceCounter(@"\Processor(_Total)\% Processor Time", 5); counters.AddPerformanceCounter(@"\Memory\Available MBytes", 5); counters.AddPerformanceCounter(@"\ASP.NET v4.0.30319\Requests Current", 5); counters.AddPerformanceCounter(@"\TCPv4\Connections Established", 5); counters.AddPerformanceCounter(@"\TCPv4\Segments Sent/sec", 5); counters.AddPerformanceCounter(@"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Received/sec", 5); counters.AddPerformanceCounter(@"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Sent/sec", 5); counters.AddPerformanceCounter(@"\Network Interface(Microsoft Virtual Machine Bus Network Adapter _2)\Bytes Total/sec", 5); counters.AddPerformanceCounter(@"\.NET CLR Memory(_Global_)\% Time in GC", 5); counters.AddPerformanceCounter(@"\ASP.NET Applications(__Total__)\Requests/Sec", 5);
The Windows Azure Team posted Real World Windows Azure: Interview with Declan Rudden, Director of Distribution at Irish Music Rights Organisation on 4/1/2011:
As part of the Real World Windows Azure series, we talked to Declan Rudden, Director of Distribution at Irish Music Rights Organisation (IMRO), about using the Windows Azure platform to deliver the organization's Online Member Services portal. Here's what he had to say:
MSDN: Tell us about the Irish Music Rights Organisation and the services you offer.
Rudden: Founded in 1995, IMRO is a nonprofit national organization that administers performing rights and distributes royalties for copyrighted music in Ireland on behalf of its members. Members include songwriters, composers, and music publishers, plus members of other international copyright organizations to which we are affiliated.
MSDN: What was the situation that IMRO faced prior to implementing the Windows Azure platform?
Rudden: In 2006, because of the emergence of additional radio stations as well as streaming and download music providers on the Internet, IMRO was faced with a massive growth in the amount of data it needed to process to serve its members. We hired Spanish Point Technologies, a Microsoft Gold Certified Partner, to build a system that would calculate royalty payments for music performances that take place in the public domain. The new system, launched in 2007, automates the royalty collection and distribution process. The system was a great success. It significantly improved the match rates and increased efficiencies therefore we were able to reduce headcount and save money.
MSDN: Describe the solution you built with the Windows Azure platform?
IMRO royalty distributions are based on the number of seconds of music a broadcaster plays in a given period.
MSDN: What makes your solution unique?
Rudden: One of the challenges that Spanish Point Technologies had to address when it built the Online Member Services portal was how it would protect sensitive member information in the cloud. We specified that we wanted data to remain largely on-premises. Only information needed to fulfill an interaction would be available through the portal. We used web services to connect the portal to the on-premises Microsoft SQL Server database, where the sensitive data resides.
MSDN: Describe how IMRO members interact with the Online Member Services portal.
Rudden: Members can sign in to the Online Member Services portal by using their Windows Live IDs. Available information includes an inventory of each artist's works, how works are stored, any instance of the work being performed or played, what royalty payments were distributed, and how payments were calculated. It plainly illustrates how if something gets played, you get paid. This gives our members comfort because our calculations are transparent and precise. We also do crowd sourcing. We allow our members to match works that we've been unable to match.
MSDN: What benefits have you seen since implementing the Windows Azure platform?
Rudden: Our members are amazed by the Online Member Services functionality. Plus, the Windows Azure platform is hosted in one of the largest data centers in Europe, and it includes a stringent SLA [service level agreement] for uptime while enabling services to scale easily as needed by transaction volumes. It's been a great success.
Read the full story at: http://www.microsoft.com/casestudies/casestudy.aspx?casestudyid=4000009116
To read more Windows Azure customer success stories, visit: www.windowsazure.com/evidence

Avkash Chauhan described a workaround for Windows Azure Worker Role Exception: System.Runtime.Fx+IOCompletionThunk.UnhandledExceptionFrame on 4/1/2011:
Application: WaWorkerHost.exe Framework Version: v4.0.30319 Description: The process was terminated due to an unhandled exception. Exception Info: System.Runtime.CallbackException Stack: at System.Runtime.Fx+IOCompletionThunk.UnhandledExceptionFrame(UInt32, UInt32, System.Threading.NativeOverlapped*) at System.Threading._IOCompletionCallback.PerformIOCompletionCallback(UInt32, UInt32, System.Threading.NativeOverlapped*)
Microsoft.WindowsAzure.ServiceRuntime Critical: 1 : Unhandled Exception: System.InvalidProgramException: Common Language Runtime detected an invalid program. at System.ServiceModel.Dispatcher.ErrorBehavior.HandleErrorCommon(Exception error, ErrorHandlerFaultInfo& faultInfo) at System.ServiceModel.Dispatcher.ChannelDispatcher.HandleError(Exception error, ErrorHandlerFaultInfo& faultInfo) at System.ServiceModel.Dispatcher.ChannelHandler.HandleError(Exception e) at System.ServiceModel.Dispatcher.ChannelHandler.OpenAndEnsurePump() at System.Runtime.IOThreadScheduler.ScheduledOverlapped.IOCallback(UInt32 errorCode, UInt32 numBytes, NativeOverlapped* nativeOverlapped) at System.Runtime.Fx.IOCompletionThunk.UnhandledExceptionFrame(UInt32 error, UInt32 bytesRead, NativeOverlapped* nativeOverlapped) at System.Threading._IOCompletionCallback.PerformIOCompletionCallback(UInt32 errorCode, UInt32 numBytes, NativeOverlapped* pOVERLAP) Microsoft.WindowsAzure.ServiceRuntime Critical: 1 : Unhandled Exception: System.InvalidProgramException: Common Language Runtime detected an invalid program. at System.ServiceModel.Dispatcher.ErrorBehavior.HandleErrorCommon(Exception error, ErrorHandlerFaultInfo& faultInfo) at System.ServiceModel.Dispatcher.ChannelDispatcher.HandleError(Exception error, ErrorHandlerFaultInfo& faultInfo) at System.ServiceModel.Dispatcher.ChannelHandler.HandleError(Exception e) at System.ServiceModel.Dispatcher.ChannelHandler.OpenAndEnsurePump() at System.Runtime.IOThreadScheduler.ScheduledOverlapped.IOCallback(UInt32 errorCode, UInt32 numBytes, NativeOverlapped* nativeOverlapped) at System.Runtime.Fx.IOCompletionThunk.UnhandledExceptionFrame(UInt32 error, UInt32 bytesRead, NativeOverlapped* nativeOverlapped) at System.Threading._IOCompletionCallback.PerformIOCompletionCallback(UInt32 errorCode, UInt32 numBytes, NativeOverlapped* pOVERLAP) (a64.69c): CLR exception - code e0434352 (first chance)
Possible Reason for this issue:
Based on investigation what we found is that the problem is caused by a known issue with Visual Studio 2010 RTM base libraries.
Solution:
The above problem is fixed in Visual Studio 2010 SP1. Install Visual Studio 2010 SP1 (VS1010 SP1) and recompile the Windows Azure Application. After that, you can test the Worker Role in the development fabric and Windows Azure.
Note: This issue is also reference here: http://social.msdn.microsoft.com/Forums/en-ZA/windowsazuretroubleshooting/thread/543da280-2e5c-4e1a-b416-9999c7a9b841
Josh Holmes awarded points to the Windows Azure Toolkit for Windows Phone 7 in a 3/31/2011 post:
The Windows Azure Toolkit for Windows Phone 7 is a starter kit that was recently released out to CodePlex. Wade Wegner, one of my former team mates when both of us were in Central Region, is the master mind behind this fantastic starter.
This starter kit is designed to make it easier for you to build mobile applications that leverage cloud services running in Windows Azure.
Screencast
In the screencast, you’ll get a great little walkthrough of the starter kit and how to get your first Windows Phone 7 application with a Windows Azure backend up and running. The toolkit includes a bunch of stuff including Visual Studio project templates that will create the Windows Phone 7 and Windows Azure projects, class libraries optimized for use on the phone, sample applications and documentation.
Why Windows Azure
Windows Azure is Microsoft’s Platform as a Service (PaaS) offering that allows you to build and scale your application in the cloud so that you don’t have to build out your local infrastructure. If you are selling an application in the Windows Phone 7 Marketplace and really don’t know how many customers you’ll end up with, you might need to scale the backend dramatically to meet the demand.
What you’ll need
Hopefully obviously you’ll need an Azure account and the tools to build and deploy the solution. The tools include one of the versions of Visual Studio (either Express which is free or higher), the Windows Azure Toolkit and then obviously the starter kit itself. I also recommend looking at Expression Blend for doing your Windows Phone 7 design and the like.
Good Luck!
By looking through the resources on the Windows Azure Toolkit for Windows Phone 7 site, you’ll see lots of great little tutorials and getting started guides.
Let me know how you’re getting on with the toolkit and what you’ve done with it. I’d like to see and possibly blog about it all…

Edu Lorenzo explained Deploying an ASP.Net webapp to Azure in a 3/31/2011 post:
I also went the same path and here is what I got… a short blog on how to move an asp.net app to the cloud.
The app I will be using is going to be the easiest app to build.. the default app that VS gives you when you create a new asp.net webapp. Why? Baby steps.. let’s get into what to modify in an existing app to make it azure ready in the future. Besides, not all apps are created equal, so in the interest of uniformity and repeatability, I’ll use the default app, so you can do it too.
SO, I start off with the default sight right. By habit, I run my visual studio as admin, and I make a new project that is an ASP.Net web application. *What about MVC? Next blog.
This should give you that default site. We stop ASP.Net development here, as what I would like to focus on is how to add this to your azure subscription.
The next thing we do now, is add a cloud application by rightclicking the solution then adding a new project of type Windows Azure Project from the Cloud template.

Give it any name you want to.
Then it will ask you what kind of role this project will be. Leave it blank, and just click OK since we want to add the existing “app” as the webrole for this project.
Your solution explorer should look something like this:

Right click the Roles folder of the cloud application and choose “Add web project in solution”
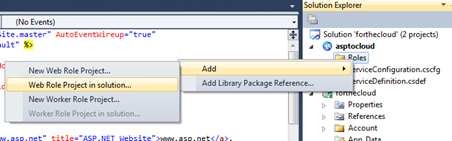
Then choose the existing app from the dialog that comes out.

And there you go! This app is now ready for publishing to Azure!
Michael Washman described a proof of concept for Migrating a Windows Service to Windows Azure in a 3/30/2011 post:
Let’s look at some of the dependencies this service has just from what we know by the above description:
- Security: The named pipe has an ACL on it so whatever machine is writing/reading the pipe will need to be authenticated.
- Distributing binaries: I’ll need to deploy the service executable and the VC++ Runtime library (which is not installed by default on Azure nodes).
- Since the bulk of my code is running in a Windows Service and not directly in the worker role how will Azure know if something went wrong?
- How will the two roles communicate? Named pipes? How is that configured?
To get started with this project I created a solution with the following projects:
- Cloud Project named "ServiceDemo"
- Worker Role named "Service Watcher"
- Web Role named "ASPXServerClient"
- Windows Service named "Service"
So let’s tackle the dependencies one at a time.
Security Dependency
Here is the security descriptor set by my service during the call to CreateNamedPipe(...):
TCHAR * szSD = TEXT("D:") // Discretionary ACL TEXT("(D;OICI;GA;;;BG)") // Deny access to built-in guests TEXT("(D;OICI;GA;;;AN)") // Deny access to anonymous logon TEXT("(A;OICI;GRGWGX;;;AU)") // Allow read/write/execute to authenticated users TEXT("(A;OICI;GA;;;BA)"); // Allow full control to administratorsIf I want to authenticate from my web role to my Windows service how can I do that? There is no Active Directory in this scenario. A relatively simple solution to this problem is to create duplicate local accounts on both the web and worker role instances. Then impersonate the local account from the ASP.NET site to access the service.
This can be accomplished by using an elevated startup task running the following commands:
Startup.cmd
net user serviceUser [somePassword] /add
exit /b 0The first line creates a local user named serviceUser with whatever password you set. The second line returns from the batch file. This particular user does not have to be part of the administrators groups due to my services service descriptor allowing the named pipe to be written to by users in the Users group. My ASP.NET code will have to authenticate as this user when it writes to the named pipe (I’ll show that a bit later).
This startup task needs to be run for the web role AND the worker role so you will need to add the following to both roles in the ServiceDefinition.csdef. Note: my startup tasks are in a folder I created in each project called “Startup” and put startup.cmd within.
<Task commandLine="Startup\Startup.cmd" executionContext="elevated" taskType="simple" />
Note the elevated requirement due to creating users.
Distributing Binaries
This one is pretty straightforward. To have additional files deploy with your worker role add them to your project (in a folder). Once added select each file in Visual Studio and change Build Action to Content and Copy to Output Directory to Copy if Newer.
For instance you will need to download the VC runtime that your service is compiled with. In my case it is the VC++ 2010 for x64 (vcredist_x64.exe). Once downloaded add the file to your Startup folder.
These steps will ensure the VC++ runtime is copied to the Azure servers when the project is published.
The next step is to add another step to the startup task for your worker role only:
"%~dp0vcredist_x64.exe" /q /norestart
This command will start the install quietly (and tell it not to reboot). The %~dp0 is a batch file constant that essentially means the current directory that the batch file is running in.
Service Installation
I also need to install my service silently. In my case the service supports a command line argument –install that performs this properly. Your service will need to perform similarly for it to install in a worker role.
The complete startup.cmd for the worker role is here:net user serviceUser [somePassword] /add
"%~dp0vcredist_x64.exe" /q /norestart
"%~dp0Service.exe" -install
exit /b 0
Monitoring the Windows ServiceAs the name of my worker role implies (ServiceWatcher) I want to monitor my Windows Service so the Azure runtime is aware of any problems and can reimage/start the role as needed.
I have a simple class (probably not real robust either!) that checks if my service is running and if not tries to start it. If it is not started after these steps it returns false otherwise true.class ServiceMonitor { public static bool CheckAndStartService(String ServiceName, int StartTimeOutSeconds) { ServiceController mySC = new ServiceController(ServiceName); if (IsServiceStatusOK(mySC.Status) == false) { System.Diagnostics.Trace.WriteLine("Starting Service....."); try { mySC.Start(); } catch(Exception) {} mySC.WaitForStatus(ServiceControllerStatus.Running, new TimeSpan(0, 0, StartTimeOutSeconds)); if (IsServiceStatusOK(mySC.Status)) return true; else return false; } return true; } static private bool IsServiceStatusOK(ServiceControllerStatus Status) { if (Status != ServiceControllerStatus.Running && Status != ServiceControllerStatus.StartPending && Status != ServiceControllerStatus.ContinuePending) { return false; } return true; } }My worker role’s Run() method is as follows:
public override void Run() { String ServiceName = "SimpleService"; int ServiceFailCount = 0; const int MAXFAILS = 5; while (true) { // if the service failed more than 5 times return if (ServiceFailCount >= MAXFAILS) { Trace.TraceError(String.Format(String.Format("{0} has failed to start {1} times", ServiceName, ServiceFailCount))); return; } try { // Check if the service is running if (ServiceMonitor.CheckAndStartService("SimpleService", 10) == true) { Trace.TraceInformation("Service is Running"); } else { // if not increment the fail count ServiceFailCount++; Trace.TraceError("Service is no longer Running"); } } catch (Exception e) { Trace.TraceError("Exception occurred: " + e.Message); } Thread.Sleep(10000); } }The worker role's Run method stays and checks the status of the Windows service every 10 seconds. If the service fails to start five times (MAXFAILS) then it returns which tells Azure that something went wrong.
Using the ServiceController class does require elevation. So in ServiceDefinition.csdef add the following line for the ServiceWatcher role instance:
<Runtime executionContext="elevated" />
How do the roles communicate?
The port for named pipes is 445. To allow communication between the web and worker roles I will need an internal endpoint opened up on the ServiceWatcher worker role.
Impersonating the Local User
My ASP.NET code will need to use impersonation to connect to the service to authenticate:
I’ve created a helper class for this:
public class LogonHelpers { // Declare signatures for Win32 LogonUser and CloseHandle APIs [DllImport("advapi32.dll", SetLastError = true)] public static extern bool LogonUser( string principal, string authority, string password, LogonSessionType logonType, LogonProvider logonProvider, out IntPtr token); [DllImport("kernel32.dll", SetLastError = true)] public static extern bool CloseHandle(IntPtr handle); public enum LogonSessionType : uint { Interactive = 2, Network, Batch, Service, NetworkCleartext = 8, NewCredentials } public enum LogonProvider : uint { Default = 0, // default for platform (use this!) WinNT35, // sends smoke signals to authority WinNT40, // uses NTLM WinNT50 // negotiates Kerb or NTLM } }Load Balancing the Internal Endpoint
One other helper function I want to mention is the following:
private String GetRandomServiceIP() { var endpoints = RoleEnvironment.Roles["ServiceWatcher"].Instances.Select(i => i.InstanceEndpoints["NamedPipes"]).ToArray(); Random r = new Random(DateTime.Now.Millisecond); int ipIndex = r.Next(endpoints.Count()); return endpoints[ipIndex].IPEndpoint.Address.ToString(); }This method is needed because internal endpoints are not load balanced by Azure. So if you configured multiple instances of your service to run you will want to load balance these calls.
Writing to and Reading from the Named Pipe
Now for the magic to actually write data to and read data from the service’s named pipe:
protected void cmdProcessText_Click(object sender, EventArgs e) { IntPtr token = IntPtr.Zero; WindowsImpersonationContext impersonatedUser = null; String ServiceUserName = "serviceUser"; String ServicePassword = "somePassword"; String ServiceInstanceIP = String.Empty; try { ServiceInstanceIP = GetRandomServiceIP(); bool impResult = LogonHelpers.LogonUser(ServiceUserName, ".", ServicePassword, LogonHelpers.LogonSessionType.Interactive, LogonHelpers.LogonProvider.Default, out token); if (impResult == false) { lblProcessedText.Text = "LogonUser failed"; return; } WindowsIdentity id = new WindowsIdentity(token); // Begin impersonation impersonatedUser = id.Impersonate(); // Resource access here uses the impersonated identity NamedPipeClientStream pipe = new NamedPipeClientStream(ServiceInstanceIP, "simple", PipeDirection.InOut); // connect to the pipe - give 10 seconds before timing out pipe.Connect(10000); String tmpInput = txtTextToProcess.Text; // null terminate for our native C code tmpInput += '\0'; // Write to the pipe service StreamWriter sw = new StreamWriter(pipe); sw.AutoFlush = true; sw.Write(tmpInput); // Wait for the result after processing StreamReader sr = new StreamReader(pipe); String result = sr.ReadToEnd(); lblProcessedText.Text = "Processed Text: " + result + " by instance: " + ServiceInstanceIP; } catch (Exception exc) { lblProcessedText.Text = "Exception occurred: " + exc.Message; } finally { if (impersonatedUser != null) impersonatedUser.Undo(); if (token != null) LogonHelpers.CloseHandle(token); } }
Simple Enough!




Michael is a Microsoft developer evangelist in Redmond.
Igor Ladnik posted Image Upload and Silverlight Deep Zoom Viewing with Azure to The Code Project on 3/27/2011 (missed when published):
This article presents Azure based software to upload image and view it with Silverlight MultiScaleImage control. Browser performs both upload and viewing with no additional installation on user machine/device (the viewing browser should support Silverlight).

Introduction
Background
It seems logical that file upload should be carried out from a simple HTML page readable by any browser. This allows the user to upload image from virtually any computer and mobile device. WCF RESTful service
IImagingSvcacts as a counterpart on the server (Azure cloud) side. This service is responsible for providing HTML page for uploading the image to Azure. For image viewing, Microsoft Silverlight with itsMultiScaleImagecontrol is employed. So the viewing browser should support Silverlight. Currently, most of browsers do meet this requirement (except probably browser of mobile devices).
MultiScaleImagecontrol is based on the Deep Zoom (DZ) technology [1-6]. Wikipedia describes DZ as follows [1]:Deep Zoom is an implementation of the open source technology, provided by Microsoft, for use in for image viewing applications. It allows users to pan around and zoom in a large, high resolution image or a large collection of images. It reduces the time required for initial load by downloading only the region being viewed and/or only at the resolution it is displayed at. Subsequent regions are downloaded as the user pans to (or zooms into them); animations are used to hide any jerkiness in the transition.
DZ requires pyramid of tiles images constructed from original image [2, 3]. The image pyramid exceeds size of original image (according to some estimation in 1.3 time in average). But this technique permits fast and smooth image download for viewing. Microsoft provides a special Deep Zoom Composer [7] tool for the tile image pyramid generation. But usage of this tool does not help in our task since this first requires installation of the tool, and second, considerably increases volume of data to be uploaded. Clearly, we have to provide a more suitable to our purposes tool for tile pyramid generation.
Design
The CodeProject articles [8, 9] and blog entry [10] were chosen as departure points for the design. The former provide algorithm and code for image tile pyramid generation. The change required was to store the images as blobs in the Azure Blob Storage rather than in database. The latter contains useful tips to set permissions to Azure Blob Storage container. While developing, I also used Cloudberry Explorer tool to inspect and manage Azure Blob Storage.
A Web Role WCF application
ImagingServicewas created with VS2010 wizard. Two WCF service components, namely,ImagingSvcandSlSvc, and a Silverlight component were added to the application. The VS2010 solution structure is depicted in the figure below:

The RESTful WCF service
ImagingSvcprovides means for uploading image from client machine / device, its processing to a DZ image tile pyramid and storage for the image pyramid to Azure Blob Storage. This service haswebHttpBinding.SlSvcWCF service intends internal-to-Azure-application communication to provide data forSlImageSilverlight-based component. The service hasbasicHttpBindingand a relative address to simplify access to it bySlImagecomponent. Interfaces and configuration of both WCF services are shown below:
Collapse | Copy Code
[ServiceContract] interface IImagingSvc { [OperationContract] [WebGet(UriTemplate = "/{data}", BodyStyle = WebMessageBodyStyle.Bare)] Message Init(string data); [OperationContract] [WebInvoke(Method = "POST", BodyStyle = WebMessageBodyStyle.Bare)] Message Upload(Stream stream); }
[ServiceContract] public interface ISlSvc { [OperationContract] string BlobContainerUri(); [OperationContract] string[] BlobsInContainer(); }
<configuration> <system.diagnostics> <trace> <listeners> <add type="Microsoft.WindowsAzure.Diagnostics. DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" name="AzureDiagnostics"> <filter type="" /> </add> </listeners> </trace> </system.diagnostics> <system.web> <compilation debug="true" targetFramework="4.0" /> <httpRuntime maxRequestLength="2147483647"/> </system.web> <system.serviceModel> <serviceHostingEnvironment multipleSiteBindingsEnabled="true" /> <bindings> <webHttpBinding> <binding name="StreamWebHttpBinding" maxBufferPoolSize="1000" maxBufferSize="2147483647" maxReceivedMessageSize="2147483647" closeTimeout="00:25:00" openTimeout="00:01:00" receiveTimeout="01:00:00" sendTimeout="01:00:00" transferMode="Streamed" bypassProxyOnLocal="false"> <readerQuotas maxDepth="333333" maxStringContentLength="333333" maxArrayLength="333333" maxBytesPerRead=" 333333" maxNameTableCharCount="333333" /> </binding> </webHttpBinding> </bindings> <behaviors> <endpointBehaviors> <behavior name="RestBehavior"> <webHttp /> </behavior> </endpointBehaviors> <serviceBehaviors> <behavior name="LargeUploadBehavior"> <serviceDebug includeExceptionDetailInFaults="true" /> </behavior> <behavior name=""> <serviceMetadata httpGetEnabled="true" /> <serviceDebug includeExceptionDetailInFaults="false" /> </behavior> </serviceBehaviors> </behaviors> <services> <service name="ImagingService.ImagingSvc" behaviorConfiguration="LargeUploadBehavior" > <endpoint address="" contract=" ImagingService.IImagingSvc" binding="webHttpBinding" bindingConfiguration="StreamWebHttpBinding" behaviorConfiguration="RestBehavior" /> </service> <service name="ImagingService.SlSvc" > <endpoint address="" contract=" ImagingService.ISlSvc" binding="basicHttpBinding" /> </service> </services> </system.serviceModel> <system.webServer> <modules runAllManagedModulesForAllRequests="true"/> </system.webServer> </configuration>
SlImagecomponent is used for viewing of previously uploaded and processed images. It containsMultiScaleImagecontrol for DZ.SlImageis publicly accessed via dedicated SlImage.html file. Being a Silverlight-based, objectSlImagecannot communicate with Azure objects directly. For this communication (e.g. to get list of stored image blobs),SlImagerelies onSlSvcWCF service. VS2010 allows the developer to easily create Service Reference onSlSvcWCF service and generate appropriate classSlImage.SlSvc_ServiceReference.SlSvcClient.SlImageuses instance of this class (proxy) for communication with main application.SlImageconfiguration fileServiceReferences.ClientConfigis shown below:</BINDING /></BASICHTTPBINDING /></BINDINGS /></CLIENT /></SYSTEM.SERVICEMODEL /></CONFIGURATION />
<configuration> <system.serviceModel> <bindings> <basicHttpBinding> <binding name="BasicHttpBinding_ISlSvc" maxBufferSize="2147483647" maxReceivedMessageSize="2147483647"> <security mode="None" /> </binding> </basicHttpBinding> </bindings> <client> <endpoint address="../SlSvc.svc" binding="basicHttpBinding" contract="SlSvc_ServiceReference.ISlSvc" /> </client> </system.serviceModel> </configuration>Code Sample
Code for this article may be tested in local Azure development environment. You should start VS2010 "as Administrator", load AzureDz.sln solution to it, build and run
AzureDzproject (highlighted in the figure above). To upload an image file, you should navigate your browser to http://127.0.0.1:81/ImagingSvc.svc/Init and from that page, perform image file upload. To view uploaded image with SilverlightMultiScaleImagecontrol navigate browser to http://127.0.0.1:81/SlImage.html. To operate the solution in Azure local development environment values ofStorageAccountNameandStorageAccountKeyparameters in file ServiceConfiguration.cscfg should be left empty.To operate the sample from Azure cloud, you should first create a Storage Account and assign its name and primary access key to
StorageAccountNameandStorageAccountKeyparameters in file ServiceConfiguration.cscfg. Then, you should create a Hosted Service place-holder on the cloud, build release version, publish it and deploy to the newly created Hosted Service. Image upload can be performed from http://place-holder.cloudapp.net/ImagingSvc.svc/Init page. Image can be viewed navigating to http://place-holder.cloudapp.net/SlImage.html.The workflow looks as following. Client sharing an image, navigates his/her browser to http://.../ImagingSvc.svc/Init on any browser-equipped device. Method
Init()ofImagingSvcRESTful WCF service is called and returns a simple HTML page to browser in response. This HTML page allows the client to upload an image labeling with a blob token (the image file name by default) with the WCF service. The image is uploaded as astreambyUpload()method of theImagingSvcWCF service. This method also processes received image to a DZ image tile pyramid and puts it to Azure Blob Storage. Now the image can be viewed using any Silverlight-equipped browser. To view the image, client should navigate his/her browser to http://.../SlImage.html and choose the image from combo-box. The selected image is shown by MultiScaleImage Silverlight control. ItsSourceproperty is assigned to the image pyramid XML blob residing in Azure Blob Storage.User uploads image file operating HTML
inputtag of type "file" of his/her browser. It causes streamed HTTP POST request containing byte representation of image. This request is received byUpload()method ofImagingSvcWCF service. Sample of such request and its structure are shown in the table below:

The request is parsed in order to extract byte array for image as well as blob token and data type. Currently, this parsing is carried out "manually" with methods of
StaticHttpParserclass (I am almost sure that there is a standard way with ready available types to parse this request, but I failed to find it quickly. PerhapsUpload()method should use parameter ofSystem.ServiceModel.Channels.Messagetype...).Discussion
Code presented in this article was tested on real Azure cloud with the largest image of 11 MB. After upload, the appropriate message appeared in the browser (some time for large images, you may get some abnormal HTML response after upload, but normally upload was successful). In local development environment for large image file
OutOfMemoryexception may occur while preparing the image pyramid. The source of exception is put in thetry-catchblock, and appropriate after-upload message informs user that not all image layers will be viewed properly. So additional efforts to improve algorithm and code are desirable.As it was stated above, usage of DZ technology required considerably larger storage space than simply storing of original image. If storage space is an issue, then the DZ image pyramid may be generated for a stored image ad hoc, or some caching mechanism (may be combining with appropriate scheduling) should be employed. For example, if it is known that tomorrow a doctor will examine X-ray images of certain patients, then DZ image pyramid may be generated for these images during the night before the examination and destroyed after the examination.
Conclusions
This article presents a tool to upload image file to Azure cloud, process the image to a Deep Zoom image tile pyramid, store the pyramid images as blobs to Azure Blob Storage and view the image with
MultiScaleImagecontrol provided by Microsoft Silverlight. All the above operations are performed with just browser without any additional installations on user machine (the viewing browser however should support Silverlight).References
[1] Deep Zoom. Wikipedia
[2] Daniel Gasienica. Inside Deep Zoom – Part I: Multiscale Imaging
[3] Daniel Gasienica. Inside Deep Zoom – Part II: Mathematical Analysis
[4] Building a Silverlight Deep Zoom Application
[5] Jaime Rodriguez. A deepzoom primer (explained and coded)
[6] Sacha Barber. DeepZoom. CodeProject
[7] Microsoft Deep Zoom Composer
[8] Berend Engelbrecht. Generate Silverlight 2 DeepZoom Image Collection from Multi-page TIFF. CodeProject
[9] Joerg Lang. Silverlight Database Deep Zoom. CodeProject.
[10] How can I put my Deep Zoom Image in Azure?History
- 25th March, 2011: Initial version
License
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4+
The Visual Studio LightSwitch Team updated their LightSwitch Development Center site after the release of LightSwitch Beta 2:

Rowan Miller posted EF 4.1 RTW Change to Default MaxLength in Code First to the ADO.NET Team blog on 3/29/2011:
We recently announced the release of ADO.NET Entity Framework 4.1 Release Candidate which included the first go-live release of Code First. The final Release to Web (RTW) is planned to be released approximately a month after the Release Candidate (RC) was published. Between RC and RTW we are not adding any new features and are focusing on fixing any bugs or issues reported by folks using the RC.
The Issue
One issue that has been raised by a number of folks is the side effects of changing the default maximum length of strings and arrays from 4000 in CTP5 to 128 in RC.
In particular this causes issues when mapping to an existing database with Code First because the new validation feature will ensure that all string and array data is shorter than 128 before trying to save. This results in a DbEntityValidationException stating:
“Validation failed for one or more entities. See 'EntityValidationErrors' property for more details.”
Inspecting the validation result states that:
"The field <property name>must be a string or array type with a maximum length of '128'."
Besides the inconvenience of having to explicitly specify the max length of most columns when mapping to an existing database we are hearing that 128 is just too short for a default and we need to chose something more appropriate.
The RC Workaround
There are two ways to resolve this issue in the RC release:
- Disable validation by setting ‘DbContext.Configuration.ValidateOnSaveEnabled’ to ‘false’
By doing this Code First will not attempt to verify the length of string/array data and even though it thinks the max length is 128 it will leave it up to the database to decide if it can store that data or not.- Configure the correct string length for each string property using the MaxLength data annotation or the HasMaxLength method in the fluent API.
This is the most technically correct solution, but we realize that configuring a length for every string/array property in your model is often going to result in a lot of repetitive configuration.The RTW Change
Based on this feedback we are proposing to change the default length of non-key properties to be ‘Max’ (this equates to varchar(max) and nvarchar(max) when running against MS SQL Server). Key properties and TPH discriminator columns will remain with a default max length of 128.
SQL Compact does not support ‘Max’ columns, when running against SQL Compact an additional Code First convention will set a default max length of 4000.
Introducing this change will cause a model generated by EF 4.1 RTW to be different from one generated by EF 4.1 RC. This means that in scenarios where Code First is generating the database you will need to re-create the database with the new column types. This only affects scenarios where the default length is used, if you have explicitly configured a maximum length then Code First will continue to honor it. If your model changes as a result of the new max length default you would receive the following exception when running the application:
“The model backing the <derived context type name> context has changed since the database was created. Either manually delete/update the database, or call Database.SetInitializer with an IDatabaseInitializer instance. For example, the RecreateDatabaseIfModelChanges strategy will automatically delete and recreate the database, and optionally seed it with new data."
 .
.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Wes Yanaga requested Azure developers to complete a Survey: Build and Deployment of Windows Azure Applications on 4/3/2011:
Microsoft is committed to understanding and improving the experience of development teams working with Windows Azure. We have put together a survey to find out more about how teams are building and deploying applications to Windows Azure, including understanding your requirements, challenges and solutions.
The survey can be accessed from http://www.surveygizmo.com/s3/507243/Windows-Azure-Build-and-Deployment
Mark Kromer (@mssqldude) promoted the Microsoft Virtual Academy for Azure – FREE on 4/2/2011:
Cloud computing is fast becoming a game-changer to hit IT professionals in recent years. Everyone is trying to figure out what you need to be successful in your role and how this effects what you do today.
The Microsoft Virtual Academy offers no-cost, easy-access training for IT professionals who want to get ahead in cloud computing.
Developed by leading experts in this field, these modules ensure that you acquire essential skills and gain credibility as the cloud computing specialist in your organization.
MVA guides you through real-life deployment scenarios and the latest cloud computing technologies and tools. By selecting the training modules that match your needs, you can use valuable new skills that help take your career to the next level.
MVA courses include:
- Introduction to SCVMM, Architecture & setup
- Creating VMs, Template & Resources in VMM
- Managing Windows Azure
- SQL Azure Security
- Identity & Access
- Data security and cryptography
- …and more at Microsoft Virtual Academy
David Linthicum warned “There's a dark side to cloud computing -- watch out for these potential cloud busters” in a deck for his 3 more cloud killers post of 3/31/2011 to InfoWorld’s Cloud Computing blog:
I haven't been shy about talking up the many of the benefits of cloud computing, but I address the dark side as well. Ironically, the caveats to cloud computing aren't typically technology related. However, they can derail your cloud computing plans if you aren't careful.
Overinflated expectations. Not a week goes by that some analyst predicts cloud computing growth at a rate never before seen in the tech world, typically tens of billions of dollars by 2012 or 2014. I suspect these numbers include many elements not related to cloud computing, as larger publicly traded technology companies attempt to "cloud wash" themselves toward higher stock prices.
These unreasonable expectations may be setting up cloud computing for failure. The industry is growing, but it's more of a gentle upward slope than a hockey stick when you isolate it to the truly relevant technologies.
Noninnovative and late strategies. I've already chimed in on HP's recent push into cloud computing, which was too late and very "me too." However, many other companies are making the same leap now that cloud computing looks like a safe bet. Pay attention: You can't enter a space once the established players are settled and expect any significant growth; you just look silly. I predict we'll see significant failures in the next few years, but they won't be the fault of cloud computing as a technology. Instead, blame the strategies and the executives behind the scenes.
Confusion over private clouds and data centers. Private clouds are a legitimate approach to architecture, leveraging many of the benefits of public clouds within your own IT infrastructure. However, not everything in your data center is now a private cloud, including the grouping of virtualized servers. Clouds have very specific features, as I've covered extensively in this blog; unless you take care in how you design and create your infrastructure, it's not a cloud.
Adam Hall presented A first look at System Center Orchestrator! in a 3/30/2011 post to Microsoft’s Integration, Orchestration and Automation blog:
At MMS last week, we unveiled the new features that will be delivered with the next version of Opalis, now announced as System Center Orchestrator.
In this post, we will take a look at the key new capabilities of Orchestrator, and how they build on Opalis 6.3 which is in market today.
I want to be very clear. Orchestrator is a ‘build on’ to Opalis 6.3, not a major rewrite. As such, we are working hard to ensure your upgrade path is as smooth as we can make it, and your investments in learning Opalis today will be completely transferrable to Orchestrator tomorrow.
So, without further ado, lets go take a look at Orchestrator! Please note that all information is subject to change, these are early builds and an early set of information.
We have grouped the functionality of Orchestrator into 4 key areas:
- Operations – the triggering, monitoring and troubleshooting of runbooks
- Developers – extensibility and application integration
- IT Business Management – reporting and analysis
- IT Pro – creating, testing, debugging and using Orchestrator in scripting

Lets take a look at each of these in a little more detail.
The Operator Console in Opalis 6.3 was based on Java and used OSS components. In Orchestrator, we move to a dynamic Silverlight console. At MMS, we showed a Prototype of the new Orchestration Console, as shown below.

What you see are all the runbooks that are part of the environment on the left hand side, and then in the main window we show the statistical information about how often and when the runbooks have executed, and what their status is.
If we drill down into the runbook that we used for demo in this session (documented here) you can see that the Action pane on the right hand side contains a number of activities, to Start, Stop and view running instances of the runbook.

When a runbook is executing, you can see the status as it progresses:

As it is clearly labeled, this is a prototype, but it is a fully functioning version, and even in this very early iteration, we are seeing significant benefits.

In addition, we also have a new PowerShell provider. As you can see below, we can mount the Orchestrator runbook library as a drive, and browse and execute the runbooks.

This new PowerShell provider allows for a variety of external integration as well as scenarios such as remote runbook management.
For the IT BUIT, we have also enabled a rich new reporting and analysis capability. You can connect to this using any solution that can accept the ODATA web service feed. For our demo, we used PowerPivot.

Once we have connected to the data feed, we can now see the information from the Orchestrator platform.

And we return all the data.

And of course, we now have a live data feed that we can publish and refresh as we wish. In the example below, we have published the data to a SharePoint site.

And last but by no means least, we have the IT Pro experience. And the great news here, is that this is changing very little.
The existing Opalis 6.3 authoring experience will remain very much the way that it is today. In fact, with all the new Orchestrator demo’s we did, they all were back-ended onto an existing Opalis 6.3 instance. So if you are wondering if you should get started with Opalis today, or wait, there is your answer … get going today!
I hope you find this information helpful in understanding our investment areas for System Center Orchestrator. As stated above, this is early in the cycle, but we were comfortable showing this at MMS, and I wanted all of you to be able to see where we are going with this critical piece of the System Center suite.
Adam










<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Shawn R. Chaput described Compliance Complexities Challenge Cloud Adoption in a 3/31/2011 post to the HPC in the Cloud blog:
Cloud and infrastructure compliance expert, Shawn R. Chaput, lends his understanding of the range of regulatory and other constraints that affect a number of users of high-performance computing. This week he took a look at the challenges of compliance burdens and what to consider when weighing cloud computing options based on lessons learned during his compliance consulting experiences. Although not intended to provide a comprehensive listing of considerations, it should provide some guidance as to some of the more commonplace examples of items warranting specific attention.
In recent experiences helping decision makers evaluate infrastructure options, we’ve encountered several clients who have decided that, given the specific sensitivity of data, the related systems should be hosted by professional hosting organizations well versed in the security of systems.
As it turns out, these data centers offer private cloud infrastructure as a service, which seemed particularly desirable to them. One of the clients in particular was looking for a provider who could guarantee the data would continue to reside within Canada as prescribed by provincial legislation as the data in question was health-related. In this specific example, this requirement became so difficult to accomplish that all other requirements seemingly fell by the wayside.
Ultimately, they found a private cloud provider but the level of security (and ultimately the compliance associated with those systems) may be insufficient for their desires.
Requirements & Obligations
The first things to understand are your regulatory and legislative obligations. Depending on your industry or geographic location, you may be subject to a variety of different laws and agreements governing the way you do business. From a security perspective, some of the more obvious ones include Sarbanes Oxley, PCI DSS, NERC CIP, and a variety of privacy regulations. Don’t expect your cloud provider to explain to you which are applicable and which they adhere to by default. For the most part, the providers are competing on price and security is not typically something organizations are really willing to pay for (although nearly all organizations expect it).
Just because the provider is a massive organization with a good track record for security and has good reference clients doesn’t mean that they’re giving you the same service at the price you’ve been quoted. You need to formalize your requirements and ensure the quotes you solicit capture them all. This likely means you need to talk to your legal counsel to understand and document these obligations. If the price is remarkably lower than the others, you need to look critically at the differences in service and specifically security.
Cloud Compliance
As I alluded, it is entirely possible that cloud services can be compliant with the obligations your organization has set forth but, by default, it’s probably good to assume the initial proposal provided by them will not be sufficient. It’s also realistic to assume that the more burdensome your requirements are, the more the solution will cost to implement and maintain.
If we refer back to that example of the Canadian health care provider looking to use cloud services, the foremost requirement they had pertained to the physical location of the data and how it must reside within the province of British Columbia. This requirement alone immediately eliminates most of the very large cloud service providers and brings it down to a handful of local providers to choose from. It’s safe to assume that the price of the niche market players would typically be higher that the massive internationals but that requirement precludes the use of the cheaper providers. Similarly, if you’re looking for a PCI DSS compliant service provider, the list is relatively short and the prices not easily comparable to non-compliant service providers.
Graham Calladine presented a 00:41:38 Windows Azure Platform Security Essentials: Module 6 – Windows Azure Role Security TechNet video segment on 3/30/2011:

About This Video
In this video, Graham Calladine, Security Architect with Microsoft Services, provides an IT Pro focused overview of the securing Windows Azure roles, certificates, endpoints, storage accounts and operations.
You’ll learn about:
- Specifics of securing various types of Windows Azure roles (Web, Worker, VM)
- Provisioning role instances
- Certificate management, creation, deployment, rollback
- Configuring public and private endpoints
- Code access security ramifications for .NET Applications
- Management of the VM Resources in the cloud, including MMC, PowerShell, Remote Desktop
- Upgrading applications
Related Resources
<Return to section navigation list>
Cloud Computing Events
Cory Fowler (@SyntaxC4) posted a Toronto AzureFest Wrap-up on 4/1/2011:
This week I presented back to back nights [March 30,31] in Toronto [despite having a cold]. The Original AzureFest Event under went a little bit of a make over, updating the slides with new features of SDK 1.3 as well as providing a little more information about how Windows Azure works under the covers.

If you’re interested in presenting an AzureFest in your area, feel free to track me down on teh twitterz. Don’t forget to check back on my blog here for some coverage on the modifications I made to the NerdDinner Project to be able to provide two files to the attendees to deploy a project using nothing but the web.

Wes Yanaga reported TechNet Events Presents: Managing Assets in the Cloud on 4/1/2011:
The continued rapid evolution of computing requires IT Pros to stay nimble and adjust their skills to meet the needs of their changing networks. Virtualized computing environments and the growth of “cloud” computing mean that the physical servers and workstations we have had on premise for years are quickly being virtualized or being placed in cloud based datacenters. How do we manage these assets that we can’t touch?
System Center Essentials 2010 and Windows Intune bridge the gap between the physical, the virtual, and the cloud for IT Pros and Network Administrators.
System Center Essentials 2010 combines several of Microsoft’s flagship System Center family of products into an easy to use, unified management solution. Combining deployment, configuration, management, reporting, alerting, configuration and more into a single console for physical and virtual assets gives IT Pros a unified view and control over all aspects of their small to medium size networks. Designed for networks with up to 50 Servers and 500 workstations, System Center Essentials 2010 gives IT Pros the information they need to monitor and maintain their entire network.
Windows Intune is a new cloud based management solution that is currently in beta. Windows Intune allows an IT Professional to begin managing many aspects of their networks immediately – without installing costly on-site servers. Simply deploy the small footprint Windows Intune agent to the workstations you wish to manage and within minutes you have the ability to: Monitor PC’s, Manage Updates, Protect PC’s from Malware, Provide Remote Assistance, Track Hardware and Software Inventory, Set Security Policies, and more!
Date
Location
Time
Registration Link
4/11/2011
Denver
9:00 AM – 12:00 PM
4/12/2011
San Francisco
9:00 AM – 12:00 PM
4/15/2011
Tempe
9:00 AM – 12:00 PM
4/18/2011
Bellevue
9:00 AM – 12:00 PM
4/19/2011
Portland
9:00 AM – 12:00 PM
4/20/2011
Irvine
9:00 AM – 12:00 PM
4/21/2011
Los Angeles
9:00 AM – 12:00 PM
Brian Hitney explained RPA: Why is my Bot Rejected? by the Rock, Paper, Azure project on 4/1/2011:
We’ve had a few people ask about getting the following message when submitting bots:
Bot contains invalid calls. Please review the official rules for more information.
While this list is subject to change, we do not allow any classes/methods from System.IO, System.Net, System.Reflection, System.Threading, System.Diagnostics, or System.GC.
That list is subject to change, and there are a few other red flags like P/Invoke or unsafe code. Sometimes, these are caused by what would otherwise seem innocuous, such as calling GetType on an object – but that’s a reflection call, so would trigger the static analysis.
Another occurrence: analysis will look for the presence of such code, not if it’s reachable. In one case, the code was never called but still present in the bot.
So, if you’re getting the above message, look for those items and if you have any questions, leave a comment here or send us an note through the www.rockpaperazure.com site!
Lynn Langit (@llangit) reported Cloud Opportunities near you–Growth of Cloud Computing on 3/31/2011:
If you live in the west coast in April you must note these cities
MSDN Presents…
Rob Bagby and Bruno Terkaly in a city near you

In this event, Rob Bagby and Bruno Terkaly will provide an overview of developing with Windows Azure. They will cover both where and why you should consider taking advantage of the various Windows Azure’s services in your application, as well as providing you with a great head start on how to accomplish it. This half-day event will be split up into 3 sections. The first section will cover the benefits and nuances of hosting web applications and services in Windows Azure, as well as taking advantage of SQL Azure. The second section will cover the ins and outs of Windows Azure storage, while the third will illustrate the Windows Azure AppFabric.
The fact is that cloud computing offers affordable innovation. At most corporations, IT spending is growing at unsustainable rates. This is making innovation very difficult.
Companies, scientists, and innovators are turning to the cloud. Don’t get left behind.
4/11/2011
Denver
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480157&Culture=en-US4/12/2011
San Francisco
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480158&Culture=en-US4/15/2011
Tempe
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480159&Culture=en-US4/18/2011
Bellevue
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480160&Culture=en-US4/19/2011
Portland
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480161&Culture=en-US4/20/2011
Irvine
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480162&Culture=en-US4/21/2011
Los Angeles
1:00 PM – 5:00 PM
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032480163&Culture=en-USWhy you should go - Cloud computing facts
The cloud makes it possible for new levels of computing power:
(1) 10's of thousands of cores
(2) 100's of terabytes of data
(3) 100,000's of daily jobs
(4) incredible efficiencies with typical levels of 80%-90% cpu utilizationStatistics
Huge Market Growth - Cloud Computing: $149 Billion projected market by 2014
Number of Servers on Earth: 60 million
Virtualization: 70% of work done will be on virtualized servers by 2014
Amount of Power in a MegaData Centers: 50 megawatts (25 - 50 times the dotcom era)
Estimated market for servers in cloud in 2014: $6.4 Billion (2010 it was $3.8 Billion)
Bloomberg Businessweek (3/7/2011, p52)
Jim O’Neal posted Take the Rock, Paper, Azure Challenge! to promot the contest on 3/31/2011:
Remember that playground game, Rock, Paper, Scissors? Well, that’s old school - it’s the 21st century, and we’re taking it to the cloud! Today, we’re launching the Rock Paper Azure Challenge!

- The contest site, http://rockpaperazure.com, contains all the information you need to play including instructions on provisioning a free Azure account, downloading the code you need to play, and a schedule of weekly webcasts where we’ll talk a bit about Windows Azure and introduce you to the game.
- To work on your own killer player (or ‘bot’ as we call it), you’ll also download a small Windows Azure application with an MVC website – the BotLab – which you can use to test out your code before you actually unleash it on the world. When you’re ready, you’ll deploy your BotLab to Windows Azure and submit your bot to the contest. From there, watch the leaderboard and see how you fare, view the game logs, and tweak your implementation to annihilate the competition.
Our first webcast is next Tuesday, and we invite you to join us then. For the next couple of days though, feel free to give it a whirl before we start the first official weekly round!





Brian Hitney offered a Rock, Paper, Azure Deep Dive: Part 1 on 3/30/2011:
If you’re not sure what Rock, Paper, Azure (RPA) is all about, check out the website or look over some of my recent posts. In this series of posts, I want to go into some of the technical nuts and bolts regarding the project.
First, you can download Aaron’s original project on github (here and here). The first project is the Compete framework, which is an extensible framework design to host games like Rock, Paper, Scissors Pro! (the second project). The idea, of course, is that other games can be created to work within the framework.
So, if you download those two projects on github, the first challenge is getting it up and running. You’ll see in a few locations there are references to a local path – by default, I believe this is “c:\compete”. This is the local scratch folder for bots, games, the db4o database, and the logfile. Getting this to work in Windows Azure was actually pretty straightforward. A Windows Azure project has several storage mechanisms. When it comes to NTFS disk I/O, you have two options in Azure: Local Storage, or Azure Drives.
Azure Drives are VHD files stored in Azure Blob Storage and can be mounted by a VM. For our purposes, this was a little overkill because we only needed the disk space as a scratch medium: the players and results were being stored in SQL Azure. The first thing we needed to do to get local storage configured is add a local storage resource:

In this case, we just created a local storage area called compete, 4GB in size, set to clean itself if the role recycles.
The next step was to remove any path references. For example, in Compete.Site.Models, you’ll see directory references like this:

Because there’s so much disk I/O going on, we created an AzureHelper project to ultimately help with the abstraction, and have a simple GetLocalScratchFolder method that resolves the right place to put files:

Now, we inject that call wherever a directory is needed (about a half dozen or so places, if memory serves). The next major change was deciding: to Spark, or not to Spark? If you look at the project references (and in the views themselves, of course), you’ll see the Spark view engine is used:

I’m no expert on Spark but having worked with it some, I grew to like its simplicity:

The problem is, getting Spark to work in .NET 4.0 with MVC 2 was, at the time, difficult. That doesn’t appear to be the case today as Spark has been revived a bit on their web page, but we started this a few weeks earlier (before this existed) and while we recompiled the engine and got it working, we ultimately decided to stick with what we knew best.
The end result is the Bot Lab project. While we’re using RPA with the idea that it can help others learn about Azure while having fun, it’s also a great example of why to use Windows Azure. The Bot Lab project is around 1 MB in size, and the Bot Lab itself can be up and running in no time (open solution, hit F5).
Imagine if you wanted to host an RPS style competition at a code camp. If you have a deployment package, you could take the package and host it locally if you wanted, or upload it to Windows Azure – hosting an extra small instance for 6 hours at a code camp would cost $0.30. Best of all, there’s no configuring that needs to be done (except for what the application dictates, like a username or password). This, if you ask me, is one of the greatest strengths behind a platform as a service.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
Randy Bias (@randybias) explained AWS Dedicated Instances, Hypervisor Security, and Multi-tenancy in a 3/31/2011 post to his Cloudscaling blog:
Most everyone in the blog ecosystem has missed both the point and some of the economics of AWS Dedicated Instances that were recently announced. Folks like The Register focus on how a single virtual instance can cost $109,324 for a year without really understanding the positioning and value proposition of this AWS offering. Another blog posting claims dedicated instances are “Un-cloudy“. Let’s be honest folks, we might be able to claim Amazon is a lot of things, but foolish is not one of them. Frankly, I think since AWS is pretty driving the definition of IaaS/”infrastructure cloud” right now, calling them ‘Uncloudy’ is fairly reasonable as well.
I’m going to put this all to bed right now. We’re going to look at the issues around multi-tenancy, security, pricing, and positioning.
Market Positioning
I’ll go into depth on this in the near future as it’s tightly related to my recent postings and presentations on ‘enterprise clouds’ (cloud-washed enterprise computing & virtualization systems). Right now though, the key thing to understand is that AWS is *already* in the business of servicing enterprise customers regardless of security concerns.Enterprises, like most other businesses, have two key adoption types: greenfield applications and legacy applications. Greenfield enterprise applications have been adopting AWS and other commodity clouds for some time now. During that same time, AWS has been very busy adding enterprise friendly features to increase the ability for legacy enterprise applications to adopt EC2.
A great example of this is Virtual Private Cloud (VPC), which originally provided simple layer-2 VLAN/Ethernet emulation combined with a VPN termination point. Now, as of their latest release it also allows creating complex networking topologies, just like in a traditional enterprise datacenter.
Dedicated Instances are yet another arrow in the AWS quiver that reduces friction for enterprise adoption of existing legacy applications. This is an enterprise focused feature. It reduces concerns around security of the hypervisor and ‘sharing’. Reduces, not eliminates.
It’s also worth noting that while billed as ‘Dedicated Instances’, Amazon has already been effectively selling dedicated VMs/instances in their HPC offering. [1]
Hypervisor Security
Whether you or I believe hypervisor security issues are relevant doesn’t matter. Some people clearly do and not sharing the hypervisor may be a requirement in some regulatory and audit situations. Providing customers a dedicated physical server and reducing sharing to only the network and (maybe) storage[2] is seen as a win by some security and compliance people.For large enterprises, getting over that security and compliance hump is important. Frankly, my recent observation is that when a massive disruption is happening the incumbents will focus on creating Fear, Uncertainty, and Doubt (FUD) in key areas. One is security. Many of the threatened enterprise IT vendors specifically throw this up as a reason to avoid adopting public commodity clouds or using their same approaches to build your own cloud. Dedicated Instances remove this obstacle.
Multi-Tenancy
Perhaps the most pernicious idea out there is that this is somehow ‘Uncloudy’ because the hypervisor is not shared. I’m not sure how this kind of thing gets started, but at it’s roots it assumes that multi-tenancy is a core property of infrastructure clouds and that it is only achieved via the hypervisor. Taking aside the definition of ‘multi-tenancy’ and whether it’s a core property, it should be noted that clouds ‘share’ many resources, of which the CPU/server is only one. They also can share storage, networking, billing systems, etc.Don’t misunderstand me. I *do* think some kind of multi-tenancy is important, but there is a spectrum of multi-tenancy from ‘a little’ to ‘a lot’. Also, what you call a ‘tenant’ is critical. Finally, tenancy happens differently in SaaS from PaaS and IaaS. The tenancy models are very very different.
So, let’s dig into this notion of hypervisor tenancy. I have a couple of diagrams to show my point. Assume we have 6 customers with 4 instances each on a cloud with 6 compute nodes. Randomly distributed we see something roughly like this:

Voila! Multi-tenancy. Everyone is happy. We have a cloud, people.
However, if we re-shuffle these instances and ‘bin pack’ them onto dedicated servers, we suddenly turn off the multi-tenancy:

What’s different here? Have we truly lost multi-tenancy? Customers are no longer sharing hypervisors and nothing has changed but that we’ve reshuffled the instances. But perhaps we haven’t lost multi-tenancy. Networking, storage, and other resources are still shared.
Let’s look at a more real world example, though, since most clouds don’t run at 100% capacity[3]:

Here we have a cloud running at about 75% utilization rate with instances randomly distributed. This is in pretty good shape, but of course, all of these open ‘slots’ aren’t generating revenue anyway. Of course, that’s part of the business model, so no harm, no foul.
Time to reshuffle!

Right, so now we’re still running at 75% for the entire cloud, but some customers are 25% utilization for their dedicated servers, some 50%, and some 100%. Our cloud wide efficiency hasn’t been reduced significantly, but per customer it has. This also means that customers are going to control the efficiency rate quite a bit more we would like, holding certain physical servers to themselves if this is the same as the AWS Dedicated Instances model.
This is where AWS rather clever pricing comes in. They simply charge a sort of ‘tax’ across a single region of $10/hr if you choose to use this capability. This tax effectively makes up for any inefficiency created by allowing customers to hold open a few more instance slots than normal.
AWS Dedicated Instances Pricing
Again, the confusion on whether this feature is ‘cost effective’ mostly comes from the Register’s biased assessment of the costs. This feature is not targeted at individual consumers, but large enterprises looking to adopt en masse. For such customers I’ve heard of monthly run rates between 100K-1M in usage charges. $12M/year for a large enterprise is a drop in the bucket.If a large enterprise spending $1M/month wants to get slightly better security, much better compliance, they would have to spend a whopping $10/hr per AWS region, roughly $7200/month[4]. That’s $86,400/year. Let’s see, that’s .7%. Is slightly better security and ability to meet compliance standards worth >1% in additional cost? I don’t know what the value is of this feature to such a large customer, but I’m certain it’s more than 1% of their total spend. Probably much more.
This pricing makes AWS Dedicated Instances extremely good value for money for a large business. Combined with the new VPC features and being able to ride Amazon’s innovation curve, constant cost reduction cycle, and the other benefits of a large commodity public cloud provider, it’s hard not to find the whole offering rather compelling.
Conclusion
Better security, better compliance, less impedance mismatch with legacy applications, ability to onboard enterprise customers, and still cloudy. This is a net win for everyone involved: AWS, enterprise customers, and the cloud community as a whole.BTW, there are whispers that AWS has significant amounts of other related features that will further reduce impedance mismatch with enterprise clouds. I expect that anyone sitting on an enterprise cloud (public or private) that doesn’t have an innovation cycle matching Amazon’s is going to get run over in the next year or two. More from us on remaining competitive soon, though.
[1] I know this because the AWS HPC GPU offering provides 2xNvidia GPUs for advanced HPC use cases; you can only have 2 GPUs in a single box because server boards only have 2 PCI-E x16 slots; in addition, each HPC system gets 8 full Nehalem cores and AWS is known not to oversubscribe cores.
[2] Ephemeral storage on instances is not shared. Only Elastic Block Storage (EBS) is shared. So it’s really your call on whether or not you share disk or not.
[3] As I said before, most target about 80% utilization rates. Anything under 70% sinks the business model.
[4] I’m glossed over the additional per instance fee here for brevity’s sake. It doesn’t change the numbers significantly. It’s still a nominal increase in costs for a significant increase in value no matter how you slice it.
Erik Meijer and Gavin Bierman asserted “Contrary to popular belief, SQL and noSQL are really just two sides of the same coin” as an introduction to their A co-Relational Model of Data for Large Shared Data Banks article of 3/18/2011 for the March 2011 issue of the Association for Computing Machinery’s ACM Queue magazine. The authors conclude:
The nascent noSQL market is extremely fragmented, with many competing vendors and technologies. Programming, deploying, and managing noSQL solutions requires specialized and low-level knowledge that does not easily carry over from one vendor's product to another.
A necessary condition for the network effect to take off in the noSQL database market is the availability of a common abstract mathematical data model and an associated query language for noSQL that removes product differentiation at the logical level and instead shifts competition to the physical and operational level. The availability of such a common mathematical underpinning of all major noSQL databases can provide enough critical mass to convince businesses, developers, educational institutions, etc. to invest in noSQL.
In this article we developed a mathematical data model for the most common form of noSQL—namely, key-value stores as the mathematical dual of SQL's foreign-/primary-key stores. Because of this deep and beautiful connection, we propose changing the name of noSQL to coSQL. Moreover, we show that monads and monad comprehensions (i.e., LINQ) provide a common query mechanism for both SQL and coSQL and that many of the strengths and weaknesses of SQL and coSQL naturally follow from the mathematics.
In contrast to common belief, the question of big versus small data is orthogonal to the question of SQL versus coSQL. While the coSQL model naturally supports extreme sharding, the fact that it does not require strong typing and normalization makes it attractive for "small" data as well. On the other hand, it is possible to scale SQL databases by careful partitioning.2
What this all means is that coSQL and SQL are not in conflict, like good and evil. Instead they are two opposites that coexist in harmony and can transmute into each other like yin and yang. Because of the common query language based on monads, both can be implemented using the same principles.
The Dryad & DryadLINQ Team reported More choice to evaluate DryadLINQ on 2/12/2011 (missed when posted):
When we first announced the public download of DryadLINQ, academic researchers and scientists were the primary audience we had in mind. Since the announcement, we received a number of inquiries from commercial users who would like to try the technology but cannot under the existing licensing. To remove this roadblock, Microsoft Research is now providing DryadLINQ under an additional license that allows for non-academic use. The new package is available from our Microsoft Connect site. It will show up in the Downloads area after you register with Connect, sign in and join our evaluation program. If you decide to evaluate DryadLINQ, we encourage you to use our forum to ask questions and provide feedback.
Another common question we get is whether Dryad and DryadLINQ are available on Windows Azure. They are not. However, if you would like them to be, you should consider casting your votes at http://www.mygreatwindowsazureidea.com. We are glad to see that some of you already have!
+3 from me for Enable DryadLINQ to Table Storage. Erik and Gavin use Dryad and DryadLINQ in their mathematic analysis of SQL vs. noSQL above.
A member of the Dryad & DryadLINQ Team recorded Some Dryad and DryadLINQ history on 2/15/2011 (missed when written):
Sometimes it’s interesting to get some context about how a research project started out, what its original goals were, and how they changed over time. This post goes into a bit of that history of the Dryad project.
From mid-2003 until early 2005, I took some time away from most of my research to work with what was then called the MSN Search product group, helping to design and build the infrastructure for serving queries and managing the datacenter behind the first internally-developed Microsoft web search engine. Towards the end of 2004 I started thinking seriously about what research project I wanted to work on when V1 of the search engine shipped. The MapReduce paper had just appeared at OSDI, and I thought it would be interesting to come up with a generalization of that computational model that would allow more flexibility in the algorithms and dataflow while still keeping the scalability and fault-tolerance. It was clear to me at the time that the Search product group would need such a system to do the kind of large-scale data-mining that is crucial for relevance in a web-scale search engine. I was also interested in medium-sized clusters, and it was an explicit goal from the start to explore the idea of an “operating system” or “runtime” for a cluster of a few hundred computers (the kind of size that a research group, or small organization, could afford), that would make the cluster act more like a single computer from the perspective of the programmer and administrator.
There is no top-down research planning at Microsoft. In my lab (MSR Silicon Valley, run by Roy Levin) we have a flat structure, and projects usually get started whenever a few researchers get together and agree on an interesting idea. I sent out an email with my thoughts on what I was calling a “platform for distributed computing,” and was able to convince a few researchers including Mihai Budiu, Yuan Yu, Andrew Birrell, and Dennis Fetterly to join in what we ended up calling the Dryad project, which got started in earnest early in 2005.
In order to have a working system we knew we needed not only an execution engine but also a storage system and a cluster-management infrastructure. Fortunately, by this time the search product group had set up a team to design and build their data-mining infrastructure, and we decided on a very close collaboration, with the product team building all the cluster services and the storage system, and the researchers delivering the execution engine. This is, in my experience, a pretty unusual arrangement at Microsoft. I think it was possible because I had recently worked closely with the search team, and so they knew I was capable of shipping code that worked (and adhered to their coding conventions, etc.), and because the product team was small and on a very tight deadline, so they were glad of the help. As a consequence, Dryad was always designed to be a ‘production’ system, and we didn’t cut some of the corners one normally might when building an initial research prototype. This had advantages and disadvantages: we didn’t get a running system nearly as soon as we could have done, but on the other hand the system we built has survived, with minor modifications, for three years in production and scaled to over 10,000 computers in a cluster, ten times the initial goal. At this point we are ready to refactor and simplify the code based on lessons learned, but overall it worked out very well.
Once we got the initial Dryad system running, we sat back and waited for users, but they turned out to be hard to convince. We had supplied an API for building graphs, and claimed in our paper that it was a wonderful thing, but nobody really wanted to use it. Meanwhile our goal of making a cluster look like a single computer had received little attention compared to the pressing problem of delivering a working, scalable, high performance execution engine to the search team. At this point our agenda diverged a little from that of the product group. They needed to get their developers using the available search data as fast as possible, and they needed to share their clusters between lots of different users and ensure that nobody would write a program that would starve out other vital production jobs. They therefore set off down a path that led to SCOPE, a query language that sits on top of Dryad and is well suited to the highest priority applications for their team, but is deliberately a little restrictive in the constructs, transforms and types it supports. We, on the other hand, were eager to get back to our original agenda of letting people write programs in the same sequential single-machine style they were used to using, but execute them transparently on our clusters.
Fortunately, just when we were wondering what to replace Dryad’s native graph-building API with, Yuan discovered the LINQ constructs, which had just been added to .NET. He saw that LINQ operators could be used to express parallel algorithms within a high-level programming language, while still keeping the algorithm abstract enough to allow the system to perform sophisticated rewrites and optimizations to get good distributed performance. Armed with this insight, he started the DryadLINQ project, and fairly rapidly had a prototype running on our local cluster.
This time the reaction of our colleagues in the lab was very different: instead of ignoring DryadLINQ they came back and asked for improvements, because they actually liked using it. The subsequent development of DryadLINQ has been closely informed by the features our users have found useful, and we have gradually gained a reasonable understanding of what programs are and are not suited to the Dryad computational model, which again will inform our work on the systems that come after Dryad.
By late 2008 we were beginning to have a minor success disaster in that a lot of people were sharing our research cluster running DryadLINQ programs, and they started to complain when one job hogged too many computers for too long, and they couldn’t get their work done. Up until that time, the logic for sharing the cluster between concurrent jobs was primitive, to say the least, and we realized that it was time to seriously look at centralized scheduling and load-balancing (not coincidentally, another key requirement to make a cluster act like a single computer). Another group of researchers got together to look at this problem, and we ended up building the Quincy scheduler that is the subject of a recent SOSP paper (and a forthcoming blog post). Since deploying that scheduler in March, we have essentially stopped getting complaints about issues of sharing, except of course when people find bugs in Quincy…
A number of other research projects have developed around the Dryad ecosystem, involving debugging, monitoring, caching, and file systems. We are still a long way from the goal of making the cluster “feel” like a single big parallel machine, but we think we are still steadily moving in that direction. Overall I think Dryad and its associated projects have been a strong validation of the old systems research dictum to ‘build what you use and use what you build.’ It does take more effort, and you can’t write as many papers as quickly, if you are trying to build a system that is solid enough for other people to depend on. But it’s very clear to us that many of the most interesting research ideas that have come out of these projects would never have occurred to us if we hadn’t had the focus that comes from helping real users address their practical problems.
<Return to section navigation list>

















0 comments:
Post a Comment